Using OADP for VM Data Protection


There are basically only three things in IT that can get you fired: theft, hitting the big red button, and f***ng up the backups.
Nightmares from Tech Support: A Thankless Job and a Near-Disaster
Gather 'round, fellow IT pros, and let's talk about a job that can get you fired faster than hitting the big red button: data protection. As a former VMware admin, I know this world intimately. My first "real" IT job was on an Enterprise Virtual Platform team, and the most crucial (and terrifying) duty that fell into my lap was managing backups.
One of my team leads once gave me a brutal but honest lesson: "There are basically only three things in IT that can get you fired: theft, hitting the big red button, and f***ing up the backups." So why would any enterprise entrust this mission-critical task to the most junior person on the team? Because under the best circumstances, it's a thankless job. Under the worst, it can get you fired, and that's usually the only time anyone pays attention. Simply put, as the junior guy, you're a "red shirt". You're expendable.

I wasn't about to lose my job over a failed VM restore, so I poured countless hours into fixing our disastrous backup situation. I inherited a Frankenstein's monster of solutions—Tivoli backing up to tape, PHD Virtual (now Unitrends), and some makeshift Robocopy scripts. We were limping along with an abysmal 30-40% nightly success rate due to neglect and inattention. We had everything from expired license keys to out-of-space backup disks and hung snapshots all over vCenter. After months of non-stop work, I got our system running reliably. We'd still get a couple of failures a night, but it was a massive improvement. Miraculously, we never suffered a major data loss... until the day our backups were truly put to the test.
The Day Everything Went Sideways
Our team was performing an ESXi upgrade. We had a custom, automated process for generating install ISOs, which had worked flawlessly dozens of times. But on this particular day, a problem arose: the on-board RAID controller on one of the ESXi hosts had failed. Our kickstart script was set to install on the "first bootable disk," which, without the RAID controller, just happened to be a Fibre Channel LUN. That LUN housed some of our most critical MSSQL databases.
I was working on another host when suddenly, a couple dozen VMs went offline, and vCenter lit up with errors. I panicked. My boss called, demanding to know why the hospitals couldn't process transactions. It took us a few minutes to unravel the disaster. I SSH'd into the host, and my stomach dropped. The LUN was mounted at "root." The ESXi install had wiped our production databases clean.
We ripped the power cables from that host and restored everything from the previous night's backup. It took four agonizing hours. We lost about half a day of financial transactions, which was a paperwork nightmare, but we got every VM back and did so within our stated SLA.
Did I get a high-five or a "great job"? No. I got chastised for weeks by the DBA team. My whole team was lectured about the cascading failures, from the misconfigured SNMP settings to the "poorly written" automation. And in a final slap in the face, our work-from-home privileges were revoked out of spite. The only win? Nobody got fired. This is why I say data protection is a thankless but absolutely vital job.
The New Backup Frontier: Leaving VMware Behind
Fast forward to today, and VMware admins are facing a new challenge: Broadcom's acquisition and the rumblings of 700-800% price hikes on licensing. Everyone is scrambling for an exit strategy, and that's where Red Hat's OpenShift Virtualization comes in.
To be honest, selling a container orchestration platform as a hypervisor is an uphill battle, and data protection has always been our Achilles' heel. The typical virtualization admin expects a simple workflow: snapshot a VM, then back up the disks and metadata somewhere else. Until recently, that wasn't possible with OpenShift. OpenShift APIs for Data Protection (OADP) relied on CSI snapshots, which kept data inside the cluster—a major no-no for real data protection.
However, with the release of OADP v1.3.1, everything has changed. With the Data Mover feature enabled and Kopia as the backend, you can now back up both block and filesystem PVCs to an external S3 bucket. More importantly, you can restore them. This is an absolute game-changer for our story around virtualization.
Admittedly, data protection on OpenShift (and Kubernetes in general) lags behind VMware, which has been around since the '90s. Kubernetes only launched in 2015, so there's bound to be a gap. But can you back up and restore your VMs on OpenShift? Yes, you can. And it won't cost you an extra dollar, unlike every backup solution for VMware. While it may lack features like change block tracking, if you just need to check the box for reliable backups and restores as you look for an off-ramp from VMware, OADP has you covered.
Prerequisites
In order to use OADP for backing up your VMs you'll need a few things
- Openshift 4.15.x with Openshift Virtualization
- OADP v.13.x operator
- an S3 bucket
My 'prod' cluster is running Openshift 4.15.12 with the latest stable OCP-V operator, 4.15.2. I'm running the latest stable OADP operator, ver. 1.3.1. I have a MinIO server on my secondary NAS that provides S3 storage.
Configuration for OCP-V
Once you've deployed the OCP-V operator on your Openshift cluster and configured a hyperconverged instance (by default, it should be kubevirt-hyperconverged in the openshift-cnv namespace), the main things you'll need in order to have properly working backups are proper CSI drivers with corresponding volume snapshot classes, and you'll need to configure your storage profiles. Although it's not 100% necessary, as a best practice it's recommended that you should use a block storage class for VMs. As I've previously written about, I use democratic-csi for iSCSI and NFS storage backed by ZFS on my primary NAS, which has all flash storage. My secondary NAS is enterprise SATA hard disks with NVMe disks for read and write cache.
The default storage class for my prod cluster is actually NFS, but you can add an annotation to your iSCSI storage class that sets it as the default for virtual machines, eg;
oc patch storageclass zol-iscsi-stor01 -p '{"annotations":{"storageclass.kubevirt.io/is-default-virt-class":"true"}}' --type=mergeWhen you deploy OCP-V, it creates a new CRD called a StorageProfile for each of your storage classes which must be configured with some basic instructions on how those PVCs can be managed by OCP-V. You'll need to patch the spec of the corresponding StorageProfile to instruct kubevirt how block PVCs can be handled, eg;
oc patch storageprofile zol-iscsi-stor01 -p '{"spec":{"claimPropertySets":[{"accessModes":["ReadWriteMany"],"volumeMode":"Block"}],"cloneStrategy":"csi-clone","dataImportCronSourceFormat":"pvc"}}' --type=mergeThen you just need to make sure you have an appropriate volumesnapshotclass for your iSCSI storage class, eg;
apiVersion: snapshot.storage.k8s.io/v1
deletionPolicy: Delete
driver: org.democratic-csi.iscsi
kind: VolumeSnapshotClass
metadata:
annotations:
creationTimestamp: "2024-05-25T16:38:30Z"
generation: 1
labels:
app.kubernetes.io/instance: zfs-iscsi
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: democratic-csi
helm.sh/chart: democratic-csi-0.14.6
name: zol-iscsi-stor01-snapclass
resourceVersion: "1666735"
uid: 7ed6b7d8-f84b-4697-8370-b0ff2557fb52
parameters:
detachedSnapshots: "true"
secrets: map[snapshotter-secret:<nil>]However, this assumes that both A. your storage class supports CSI snapshots and B. the appropriate snapshot controller is deployed either as part of the CSI driver deployment, or can be added after the fact. Either is the case with Democratic CSI, but not all CSI drivers support snapshots. For example, if you're using ODF which is generally natively compatible with Openshift, cephfs and ceph-rbd storage classes support snapshots, but the two object storage classes ODF provides - ceph-rgw and noobaa - do not. If your storage class does not support CSI snapshots, I think it's still theoretically possible to do backups with kopia on OADP, but I have not successfully tested this yet.
Configuring S3 storage
I won't go over how to deploy MinIO as that's not within the scope of this blog post, but I will say that if you want SSL enabled for your S3 server, it's a lot easier to use Nginx to reverse proxy to your MinIO server and handle the SSL termination than it is to try and get MinIO to handle SSL itself.
On your S3 server, you'll need to create the appropriate bucket and path for your backups, which will be defined in the DataProtectionApplication in the next step. In my case, the bucket I'm using is oadp > prod.
Configuring OADP
Setting up OADP is actually not that complicated. Basically, you just need to install the operator, create a secret with the credentials for your S3 storage and then create a DataProtectionApplication to point OADP at your S3 server.
S3 secret
cat << EOF > credentials-velero
[default]
aws_access_key_id=YOURACCESSKEY
aws_secret_access_key=YOURSECRETKEY
EOF
oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
then you create the data protection application, eg;
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: prod-ocp
namespace: openshift-adp
spec:
backupLocations:
- velero:
config:
insecureSkipTLSVerify: 'true'
profile: default
region: us-east-1
s3ForcePathStyle: 'true'
s3Url: 'https://minio.cudanet.org:9443'
credential:
key: cloud
name: cloud-credentials
default: true
objectStorage:
bucket: oadp
prefix: prod
provider: aws
configuration:
nodeAgent:
enable: true
uploaderType: kopia
velero:
defaultPlugins:
- openshift
- aws
- kubevirt
- csi
defaultSnapshotMoveData: true
defaultVolumesToFSBackup: false
featureFlags:
- EnableCSI
snapshotLocations:
- velero:
config:
profile: default
region: us-east-1
provider: awsOADP will assume that your S3 storage is on AWS. I use MinIO as my S3 server locally but you can use dummy values for things that don't actually apply to your server like region: us-east-1.
Once you create your DataProtectionApplication, OADP will validate the configuration and then create a couple other custom resources including a VolumeSnapshotLocation and a BackupStorageLocation for your S3 server. If you run into issues, make sure that things like your URL and credentials are correct.
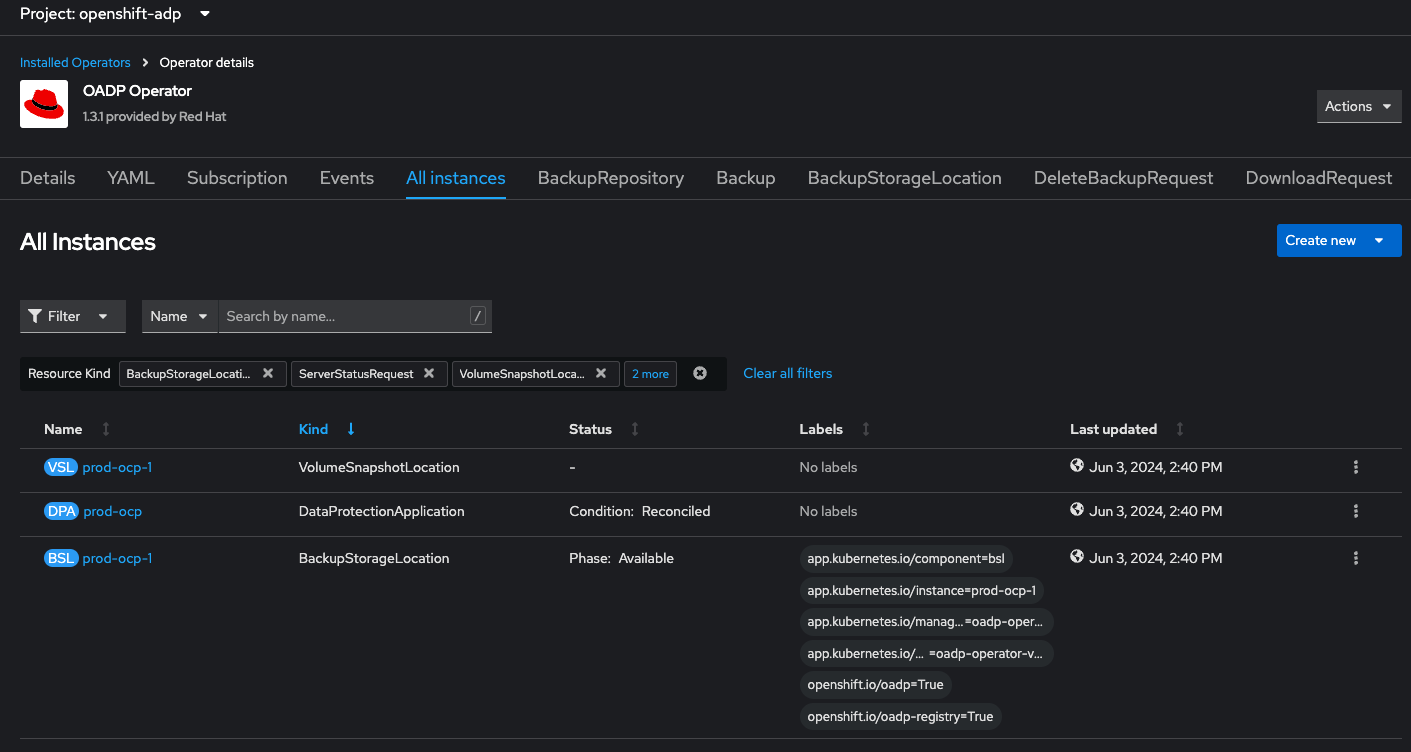
Testing Backup and Restore
I started by creating a simple Fedora VM from one of the provided templates and created a single text file in the fedora users home directory with the words "Hello world" in it, just to prove that when I restore it's not just doing something screwy like deploying a new VM from template.
Then I created a backup of the running VM. Truth be told, it's probably easier to just use CLI to do your backups, eg;
echo "alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'" >> ~/.bash_profile
source ~/.bash_profile
velero create backup test --snapshot-move-data true --snapshot-volumes true --include-namespaces testWith the typical VMware admin in mind, you would accomplish the same thing using the Web UI by navigating to create new > backup and making sure to specify those values by checking the appropriate boxes on the form, eg;
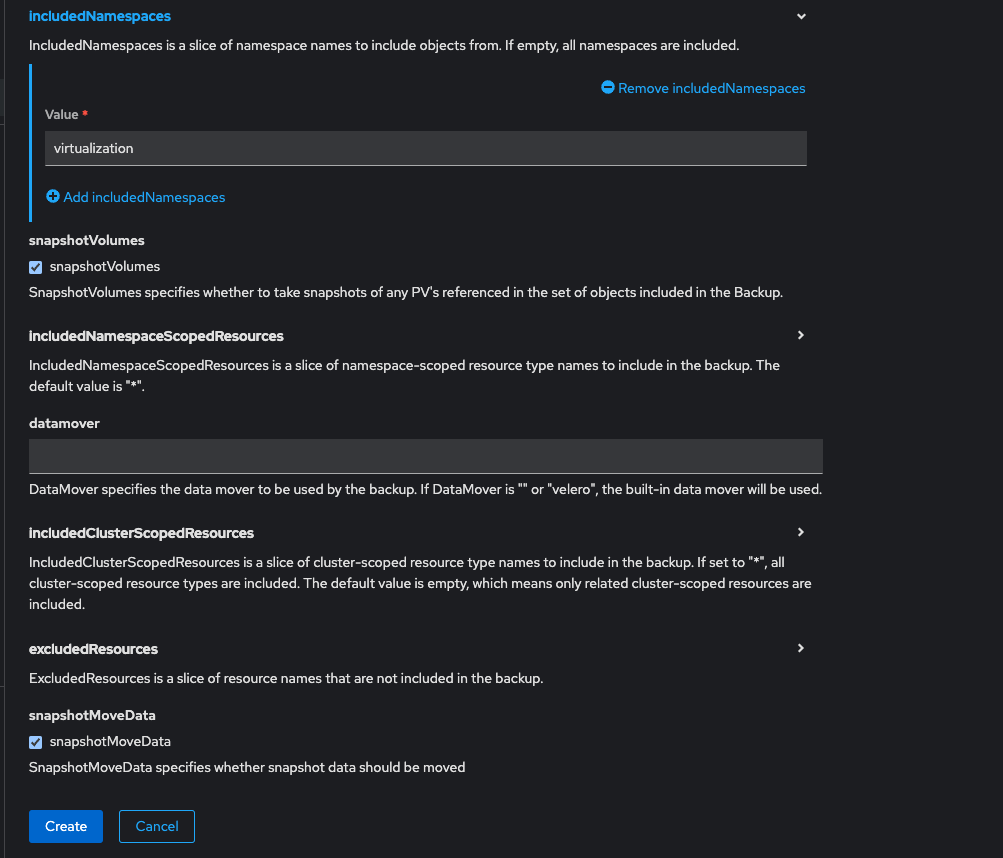
Once you kick off your backup, a few things will happen. One or more volumesnapshots will be created for each PVC in your namespace, a backuprepository will be created, and a dataupload will be created for each PVC in your namespace, which will then spin up a backup pod in the openshift-adp namespace, which will be running a kopia job to copy your block PVC data from your Openshift cluster to your S3 bucket. YMMV, but OADP uploads data to my MinIO server in ~20MB chunks
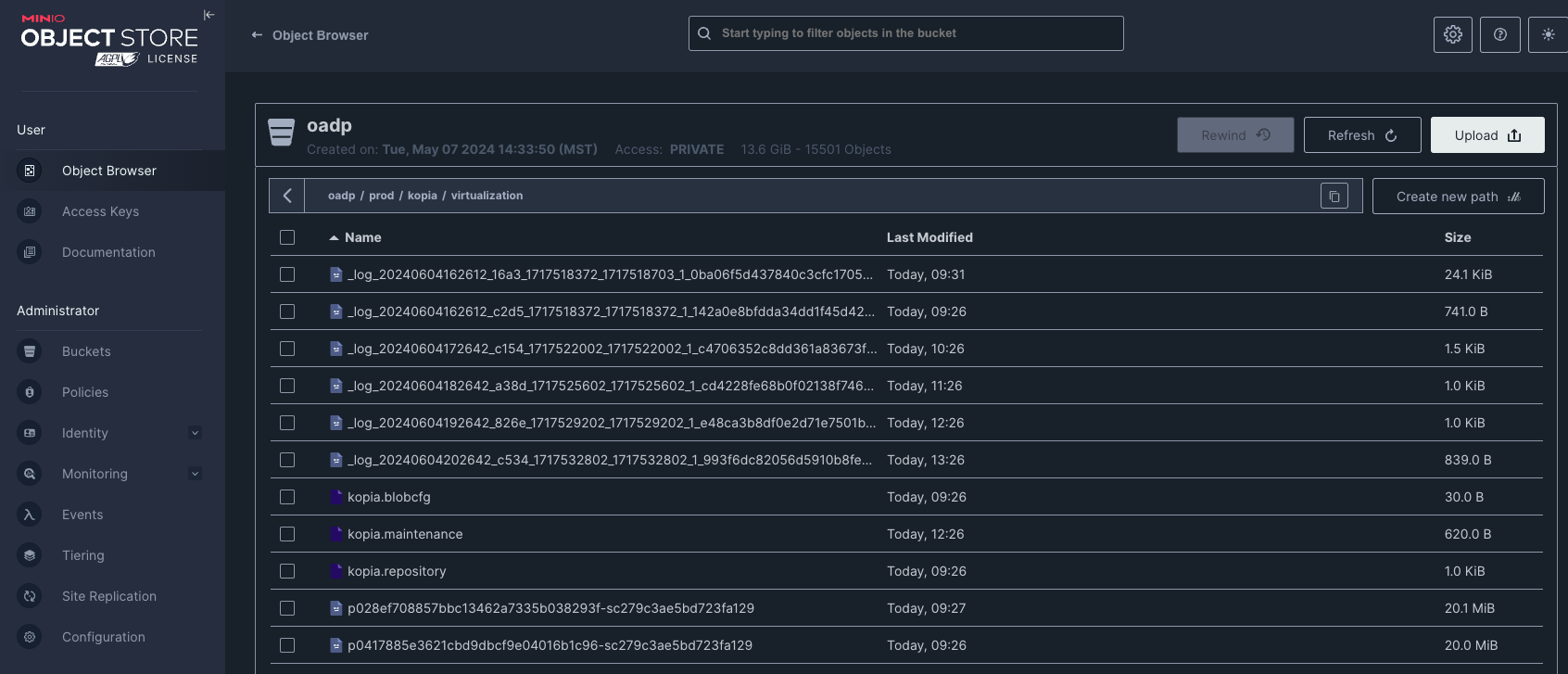
Once the backup had been completed (only takes a few minutes, these VM templates are only a few GB) I destroyed the VM and made sure the PVC was gone, and then I created a restore task.
Again, you can do this easier with CLI, something like eg;
velero create restore --from-backup test --restore-volumes trueOr you can do so using the Web UI, eg;
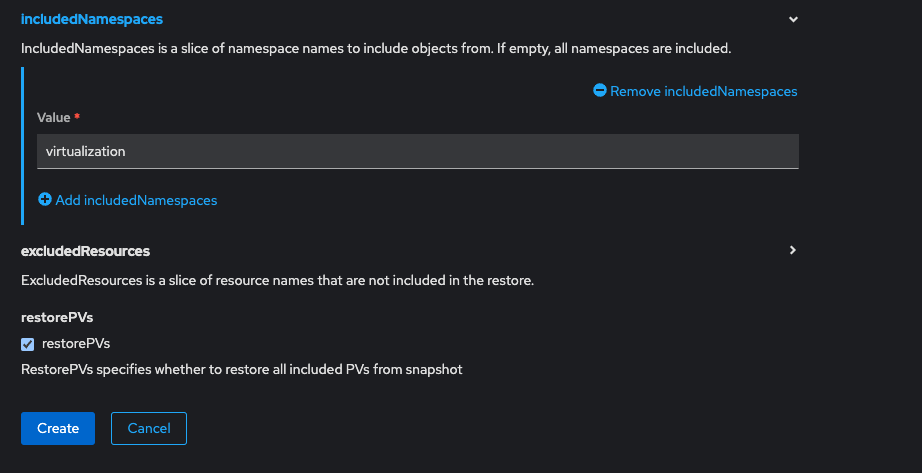
Once you kick off the restore, it will create a restore object and a datadownload for each PVC in your namespace. After a few minutes (depending on the size or your VM... like I said, mine was only a few GB) a VM and a PVC was created in my virtualization namespace, the PVC was eventually bound and the VM booted back up.
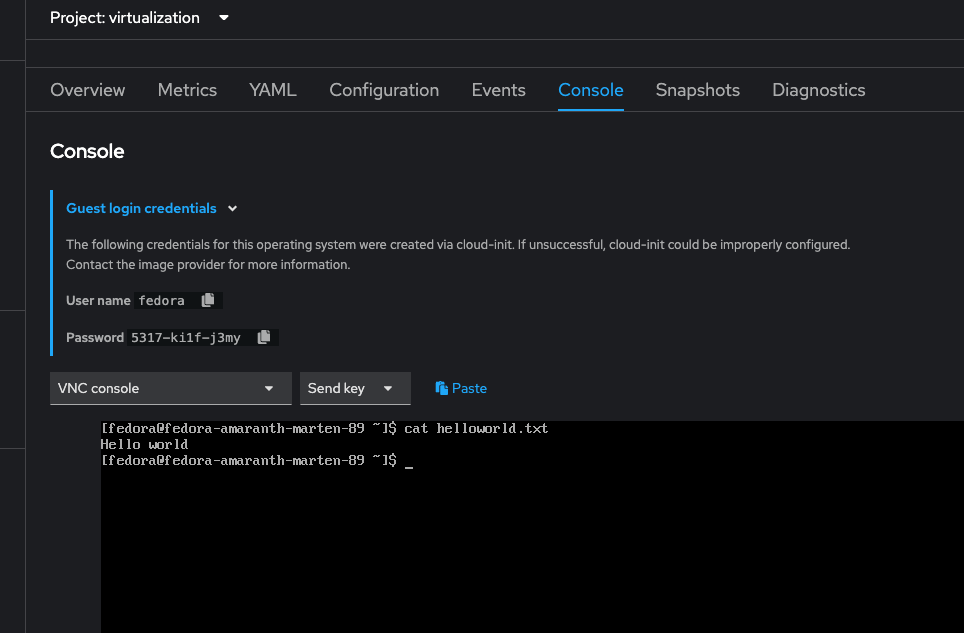
Success!
Scheduling VM Backups
A one-off backup of a VM is fine, but having regular backups (and perhaps more importantly - testing restores!) is a must for any IT organization for critical VM workloads. A backup schedule in OADP is set up as a cron job, like this:
apiVersion: velero.io/v1
kind: Schedule
metadata:
name: schedule-virtualization-nightly
namespace: openshift-adp
spec:
schedule: 0 0 * * *
template:
includedNamespaces:
- virtualization
snapshotVolumes: true
snapshotMoveData: true
storageLocation: prod-ocp-1
which would run a nightly backup at midnight. Worth noting, cron time on Openshift is expressed in UTC, so you may want to adjust accordingly, eg; midnight Greenwich Mean Time is only 5PM here in Phoenix, AZ so I would use 0 7 * * * for nightly backups at midnight. That's it.