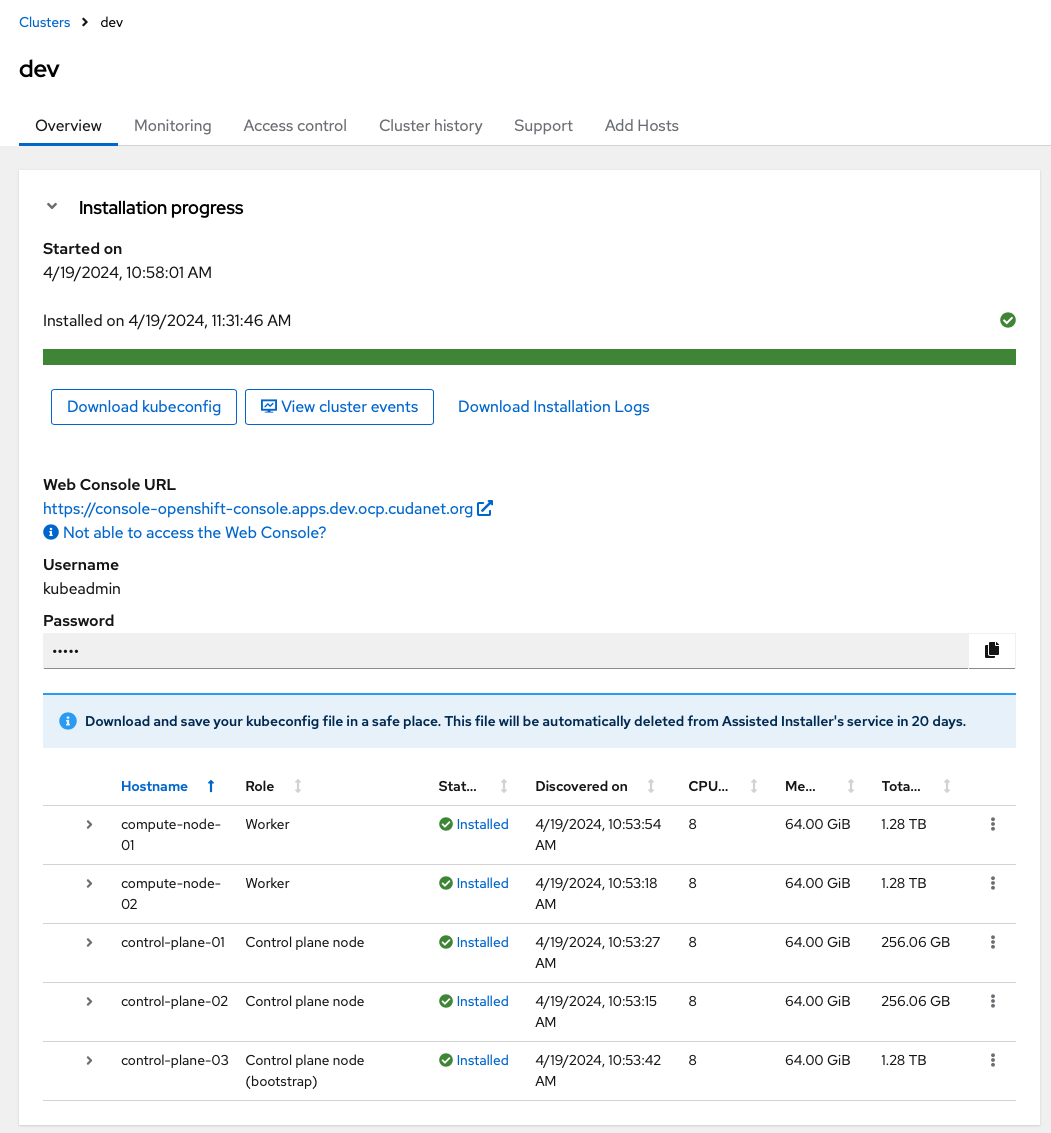
PXE Booting the Assisted Installer

They say that necessity is the mother of all invention. In my case, it's a combination of impatience and laziness. I wanted to deploy a new Openshift cluster on bare metal, but I didn't want to have to buy a bunch of thumb drives, burn a bunch of thumb drives, walk down to my laundry room and plug said thumb drives into nodes, reconfigure said nodes to boot from USB in BIOS, etc. etc. etc. Using the assisted installer is amazing, especially for bare metal deployments where you don't have any kind of IPMI (it me). However, if you go with the assisted installer, you need to be able to boot all nodes in the cluster simultaneously from the discovery image, which means you need either 1 thumb drive per node, or you need another method of service the discovery image to all nodes.
PXE boot has entered the chat
I already am using PXE boot to deploy my prod cluster, so a lot of what I'm doing here is just re-treading work that I've already done. In broad strokes, for PXE boot to work, you need to have a functioning DHCP server configured to point at a TFTP server, and the TFTP server needs to be configured to serve a couple of files in order to boot Linux, namely, a kernel image usually called vmlinuz, an initial RAM disk, usually called initrd or initramfs, and a root disk image and occasionally some other files, which are generally served via another protocol, eg; NFS, FTP or HTTP.
I recently wrote about my migration to TrueNAS Scale, and how I am using Democratic CSI as my primary (now only) storage platform. Previously I was using ODF for storage on Openshift and TrueNAS for basically everything else. Due to the overall complexity of ODF/Ceph, it's high resource consumption and the fact that it's virtually impossible to access data stored on Ceph outside the context of kubernetes, I decided that for my use, it made much more sense to standardize on TrueNAS for my storage needs.
Over time, I ended up scaling up my "prod" cluster to 10 nodes, which looking back now, I'm realizing was really only to support running ODF and still have enough resources available for other workloads. After removing ODF, I ended up with a mostly empty Openshift cluster, and an opportunity to reswizzle some things in my lab. I decided it was a good idea to split my prod cluster in half and redeploy 5 of the nodes as a separate dev cluster.I mean, it is a good idea. Now I can better utilize my hardware, and it gives me a place where I can test out things like upgrades and changes without blowing up my prod cluster... kind of like how you might run Openshift in a real enterprise environment (gasp!) But this is home lab! We "move fast and break things" here... yeah, I enjoy uptime as much as anyone else does. It may just be a home lab, but I still serve some externally facing applications from my prod cluster, not the least of which being this here blog you're reading. So, while nothing I host is terribly important, it is important to me.
Once I decided it was time to chop my prod cluster in half and create two clusters, I had some work to do. In no (okay... some) particular order -
- Reconfigure vfiopci for GPU passthru (was previously pinned to these 5 nodes, now I just have the masters configured for pod pass thru and the 2 workers for VM pass thru. You can't have both with Intel)
- decom the nodes (wipe disks, shut down, remove from OCP)
- move the nodes to a different VLAN (I like to keep my OCP clusters on separate networks... not 100% necessary, but it is a good practice)
- create new DHCP reservations
- create new DNS records (including the wildcard for the ingress, which requires a custom config which I wrote about here)
- configure TFTP for PXE booting on the new VLAN
My prod cluster is a UPI (meaning "hard mode", you do all the leg work) cluster. I have all the necessary services; dhcp, dns and haproxy, running on OPNsense. For whatever reason, the HAProxy plugin on OPNsense will not allow you to bind ports 80 and 443 to multiple VIPs (frontends), so going UPI for my dev cluster isn't really an option. Besides, UPI sucks! The assisted installer is awesome, and that is how I set up my infra cluster.
How to PXE boot the Assisted Installer
Creating a new cluster with the Assisted Installer always begins with a visit to console.redhat.com. Log in to console with your Red Hat credentials and then navigate to Services > Containers > Clusters and then click on the Create cluster button. Select Datacenter and the click the Create cluster button under the Assisted Installer section at the top.
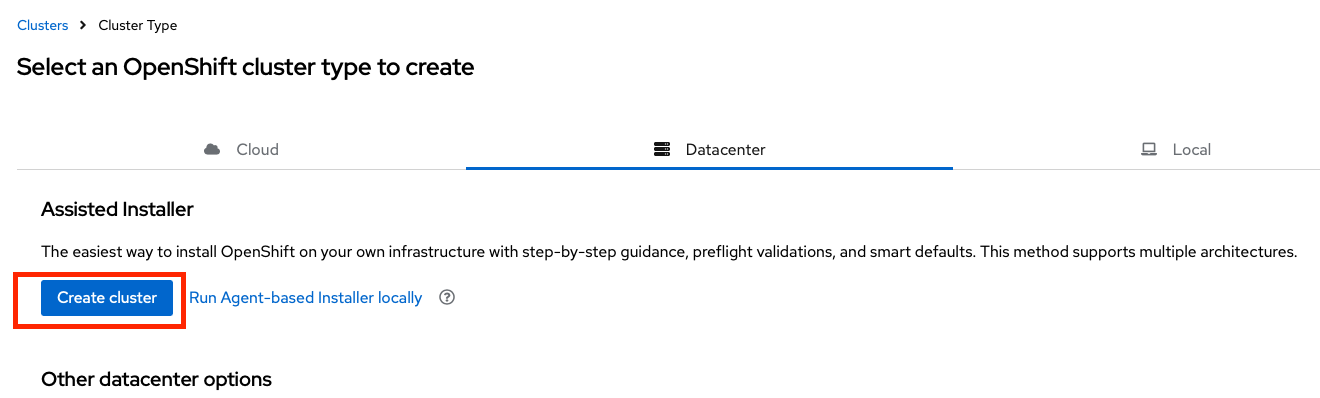
Give your cluster a unique name (it must resolve to the DNS entries you created for your cluster) and then click next. On the second screen you can select which operators you want to use, eg; Openshift Virtualization, ACM, etc. I typically prefer to do these configurations post-deploy, so I just leave them turned off. Then click next.
In order to generate your discovery ISO image, click the Add hosts button - yeah, not as intuitive as maybe a button that says download discovery ISO, but that's not my problem. Add an SSH key if you wish (it's a good idea, especially on bare metal, but it should be said that under normal circumstances, you really should only interact with you nodes via the API, eg; oc debug node/compute-node-01). Click the Generate Discovery ISO button and download your ISO image.
Now, with our ISO image in hand, we need to grab a few files from it and upload them to our TFTP server. Specifically, we need ASSISTED_INSTALLER_CUSTOM.IMG, IGNITION.IMG, INITRD.IMG, VMLINUZ and ISOLINUX.CFG.
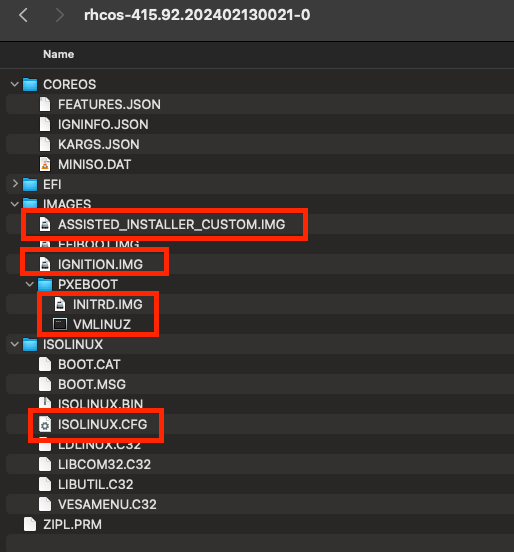
If we look at the contents of the ISOLINUX.CFG file, it tells us exactly how it boots. The process of booting an ISO image is basically no different from booting Linux via PXE, you just need to tweak a few things.
label linux
menu label ^RHEL CoreOS (Live)
menu default
kernel /images/pxeboot/vmlinuz
append initrd=/images/pxeboot/initrd.img,/images/ignition.img,/images/assisted_installer_custom.img ignition.firstboot ignition.platform.id=metal coreos.live.rootfs_url=https://api.openshift.com/api/assisted-images/boot-artifacts/rootfs?arch=x86_64&version=4.15
On my OPNsense box, I have PXE booting (TFTP) set up. The TFTP root exists at /usr/local/tftp and the important files exist at /usr/local/tftp/images and /usr/local/tftp/pxelinux.cfg/. In the pxelinux.cfg (we're going to copy the ISOLINUX.CFG file and tweak it), all paths are relative to the tftp root directory. So, a file that lives at /images is actually /usr/local/tftp/images. Just like PXE booting RHCOS for a UPI install, the initrd an vmlinuz files reside in the images directory, and as we can see in the assisted installer's boot menu entry, the ASSISTED_INSTALLER_CUSTOM.IMG and IGNITION.IMG also do.
So let's start by uploading the necessary files to OPNsense
scp -r /Volumes/rhcos-415.92.202402130021-0/IMAGES/ASSISTED_INSTALLER_CUSTOM.IMG [email protected]:/usr/local/tftp/images/
scp -r /Volumes/rhcos-415.92.202402130021-0/IMAGES/IGNITION.IMG [email protected]:/usr/local/tftp/images/
scp -r /Volumes/rhcos-415.92.202402130021-0/IMAGES/PXEBOOT/INITRD.IMG [email protected]:/usr/local/tftp/images/
scp -r /Volumes/rhcos-415.92.202402130021-0/IMAGES/PXEBOOT/VMLINUZ [email protected]:/usr/local/tftp/images/isolinux, our PXE server is actually case sensitive, so we need to be aware of absolute paths and actual names of files. On our tftp server VMLINUZ is not the same as vmlinuzWith our files in place, we just need to tweak the menu config to reflect the paths where the files reside, like this:
label linux
menu label ^RHEL CoreOS (Live)
menu default
kernel /images/VMLINUZ
append initrd=/images/INITRD.IMG,/images/IGNITION.IMG,/images/ASSISTED_INSTALLER_CUSTOM.IMG ignition.firstboot ignition.platform.id=metal coreos.live.rootfs_url=https://api.openshift.com/api/assisted-images/boot-artifacts/rootfs?arch=x86_64&version=4.15That's really the only thing special we need to do in order to be able to PXE boot the assisted installer ISO. Then, what I like to do with my PXE server is confine specific configs to specific machines via their MAC address, so that I don't have problems like... a Windows VM rebooting and accidentally getting re-imaged as an RHCOS node. Not very likely to happen, but still a good idea to take the necessary precautions.
Now lets copy our ISOLINUX.CFG file to the TFTP server
scp -r /Volumes/rhcos-415.92.202402130021-0/ISOLINUX/ISOLINUX.CFG [email protected]:/usr/local/tftp/pxelinux.cfg/assisted-installer
Then to create a MAC specific boot config, you need the MAC address of the machine you want to boot. The format will always be 01 followed by the MAC address of the machine, all in lower case, and separated by dashes, and not colons, like this. 6C:4B:90:6c:6F:34 would become 01-6c-4b-90-6c-6f-34. You can just use symlinks, which work great, especially when you have multiple hosts that need to boot from the same source.
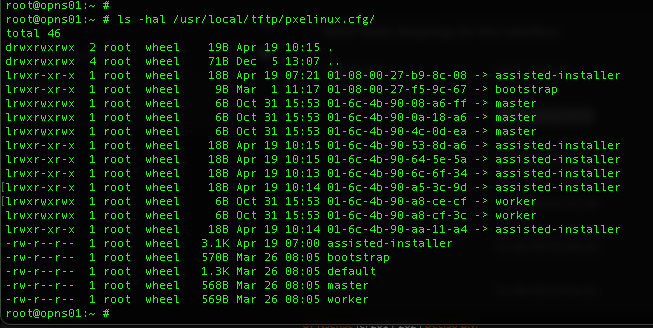
Note the entries symlinked to assisted-installer. I have a test VM 01-08-00-27-b9-8c-08 set up to test PXE booting.
Satisfied that my PXE config is working, I was off to the races. I just created the necessary symlinks for all of my nodes, powered them on and waited about 20 minutes for the cluster to come up.