Openshift for the Homelab

I've been working with Openshift 4 pretty much every day for going on 5 years or so now. Before that, I dabbled with Openshift 3, and I've been know to spin up DIY Kubernetes clusters from scratch, so it's easy for me to forget that there can a pretty steep learning curve to Openshift, and Kubernetes in general. However, it doesn't have to be hard getting started. There has been an absolute ton of work put into Openshift over recent years to make it easier and more accessible than ever.
Nobody could have possibly predicted the Broadcom acquisition of VMWare and the fallout that it has caused. As a result, the entire IT world is currently scrambling for an exit strategy. As they say, hindsight is 20/20, but we (Red Hat) really could not have picked a worse time to kill off our own virtualization platform (RHV). Sure, we offer a couple of other virtualization solutions including RHEL with KVM, Openstack and Openshift Virtualization, but none of those offerings are really direct competitors to vSphere. The fact is, RHV never really gained any traction in the enterprise. It was always too complicated, and frankly not "VMWare-y" enough for average sysadmins to easily adopt it coming from vSphere. Towards the end of it's lifecycle, most of the rough edges of RHV had been sanded off and it really was a pretty solid platform. However, it was announced in 2022 that RHV would be going end of life and our recommendation at the time –a recommendation which still stands today– was to migrate virtual machines from RHV to Openshift.
One can certainly speculate as to why certain decisions were made, but the fact remains that RHV is dead, long live Openshift. Internally at Red Hat there has been a chorus of voices echoing the sentiment that we should reverse course on the decision to sunset RHV, but those cries have fallen on deaf ears. Personally, I would like to see RHV live on, but from a business standpoint I fully understand why we killed it and actually agree that - painful though it may be, especially in light of the Broadcom acquisition - it was the right decision given the information we had at the time. RHV was never a serious contender in on-prem virtualization, so why dedicate an entire division of the company to building and maintaining a platform that virtually (no pun intended) no one used? Not only that, but the writing is on the wall; the world is simply moving away from virtualization. The hypervisor wars were fought long ago by greybearded keyboard jockeys with pony tails and Birkenstocks. Your average dev probably wasn't even born yet when VMware ascended to dominance in on-prem virtualization. Nobody cares about VMs anymore (other than the career VMware sysadmin), they only care about applications. We're entering into a "post VM" era of IT. That's not to say that VMs are dead or that they're ever going away, just that containers and microservices, and whatever comes after that are where the vast majority of growth in IT is now, and for that we have the strongest positioning as an application and development platform with Openshift - oh, and yeah. It can run your VMs too.
As they say, necessity is the mother of all invention and we really burned the ships on this one. We doubled down on Openshift as our premier virtualization platform and an absolutely astonishing amount of work has been done to improve every part of the experience, and not just for virtualization. It is true that MTV (no, not the one you're thinking of. I'm referring to the "Migration Toolkit for Virtualization") has made it incredibly easy to onboard workloads from other virtualization platforms – including vSphere. Virtualization aside, nearly every aspect of Openshift has simply gotten better. Installing Openshift used to practically require a PhD in Kubernetes, but things like the Assisted Installer, agent-based installer and the sheer number of platforms we support for IPI (installer provisioned infrastructure) have made it easier than ever to get started with Openshift. We've made massive strides in making Openshift scalable - both up and down. You can deploy Openshift as the standard "3x3". You can scale up to theoretically thousands of nodes. You can deploy Openshift as a "compact cluster" (aka; 3 schedulable control planes). You can deploy it as a SNO (Single Node Openshift) cluster. You can even deploy Openshift on top of Openshift with HCP (Hosted Control Planes, aka; "hypershift") opening the door to "Openshift as a Service" both on-prem and in the cloud, and for edge use cases, there's even Microshift which gives you the ability to run your container workloads at the far edge and manage them all with a single set of tooling.
Perhaps I'm a little bit biased, but I would actually argue that Openshift is the best alternative to VMWare currently available. Is Openshift a drop-in replacement for vSphere? Certainly not. Nobody has ever said that (except maybe some overly enthusiastic marketing types), because the two platforms are fundamentally different things with completely different goals. About the only intersectionality between the two is the fact that they both happen to be hypervisors. Openshift is a fully software defined, developer-centric application platform, whereas vSphere is simply a place to park your VMs. Virtualization on Openshift is practically an afterthought.
But what about home labbers? Lots of people - not just corporations with million dollar ELAs - have been directly impacted by the Broadcom acquisition of VMware. Just scroll through r/homelab on Reddit and you're going to see some pretty colorful opinions about it, and the general consensus is that VMware is no longer a viable option for the home lab. Broadcom killed the free version of ESXi, which admittedly wasn't a huge loss, but it is a bellweather of more changes, particularly consumer hostile ones, to come. Where is an orphaned home labber to turn? It's not exactly a secret that ProxMox is capturing a lot of the VMware refugees, and that's not necessarily a bad thing. ProxMox provides a host of enterprise grade features for the low price of... free. So it's not surprising that ProxMox is the darling of the home lab community. Truth be told, under the hood ProxMox is actually the exact same bits as Openshift Virtualization (or RHV/oVirt, Openstack or RHEL Standalone Hypervisor). It's all Linux + KVM + Libvirt + Qemu. The only thing that differs between any of those platforms is the management interface. If ProxMox checks all the boxes for you, then by all means use that. It's certainly easier to get a ProxMox cluster up and running than it is to deploy Openshift.
However, I would like to make a case for Openshift in the homelab. At Red Hat we have a pretty active home lab community, with people running everything from full server racks of enterprise gear to labs cobbled together with NUCs and Raspberry Pis, and one thing that almost all of us have in common is that all of this is really just a means to an end - to run Openshift. So if the goal is to run Openshift, why complicate things by adding a virtualization layer when you could cut out the middle man and just go Openshift on bare metal (which, by the way is the only requirement to run Openshift Virtualization)?
For the average home labber, the idea of going all in on Openshift (or just Kubernetes in general) can seem scary. Not only that, but a common complaint I often hear is that Openshift has too much overhead. While it is true, Openshift does consume more resources than your typical hypervisor platform, I'd argue that it may not be anywhere near as heavy as you might think. Granted, comparing something like vCenter to Openshift is not exactly apples-to-apples, but you'll find that resource consumption for the two is actually pretty close. A "tiny" VCSA consumes 2 CPUs and 14 GB of RAM, but I know from personal experience that it really struggles with anything less than 4 CPUs and 16GB of RAM. The minimum configuration supported by Openshift is a single node cluster with 8 CPUs and 16 GB of RAM, but once deployed, actual utilization is going to hover around 4-5 CPUs and maybe 8-9GB of RAM. So technically, just about any relatively modern laptop would be able to handle running Openshift.
Also, it's important to point out that resource consumption does not scale linearly. The more nodes you add, the smaller a percentage of resources consumed by the management interface, just like with vCenter. You can add more ESXi hosts to a cluster and while resource utilization per host does tick up slightly, it's hardly a consideration. The same holds true with Openshift nodes. Compared to a vanilla k8s cluster, yeah it's pretty heavy but it's actually not that much more overhead than vCenter (or ProxMox VE, or the oVirt Managed Engine for that matter). Ultimately, what you get with vCenter is just a place to host VMs. With Openshift you get that, plus Kubernetes, a whole slew of developer tooling and a really nice web frontend.
Personally, my lab consists exclusively of consumer grade hardware, with the sole exception of my 48 port HPE ProCurve managed switch. Aside from that, everything else is just inexpensive used Lenovo Tiny PCs and a couple old Mac Pros purchased on Ebay. You can read up on "Project Tiny Mini Micro" to learn more about this kind of hardware, but these 1 litre class ultra small form factor PCs are a pretty popular option for home labs for several reasons. For startes, they're relatively inexpensive. I sourced the first 4 nodes that make up my prod cluster for $200 - if you're following along at home, that's $50 each. Second, they actually pack a pretty good amount of resources in a small package. Each of my nodes is a Lenovo M710Q Tiny which has an i7-7700T (4 cores/8 threads at 3.8Ghz) and unofficially, they support up to 64GB of DDR4. Third, they don't generate anywhere near the kind of heat and noise enterprise gear can - my entire lab is damn near silent, the fans only really ramp up when I am really hammering the CPU and even then it's not that loud. And of course, it goes without saying but they're small. My entire lab fits on a shelf in my laundry room. One of the best things about these tiny PCs is that they have allowed me to incrementally grow my lab over time, starting out with the original 4 nodes which I eventually expanded to 6, then 8 then 10 as my needs changed. I tried running vSphere 7 on my lab, then moved to RHV until it was announced that RHV was going EOL, at which point I went to Openshift. I simply drew a line in the sand and said "no more VMs". It was a lofty goal, and not one I was realistically able to achieve, but ever since then my approach to hosting services has been containers first unless there's a good reason why an can't or shouldn't be containerized. These days the only real VM workloads I have are Active Directory for LDAP/Kerberos which can't run on containers, a Gitlab Omnibus install that I'm in the process of migrating to the Operator install on Openshift, and a handful of Windows, Linux and macOS bastion hosts that I use for administrative tasks in my lab, and I am running a virtualized external Ceph cluster for ODF since it's not possible to ODF in external mode on containers.
Networking
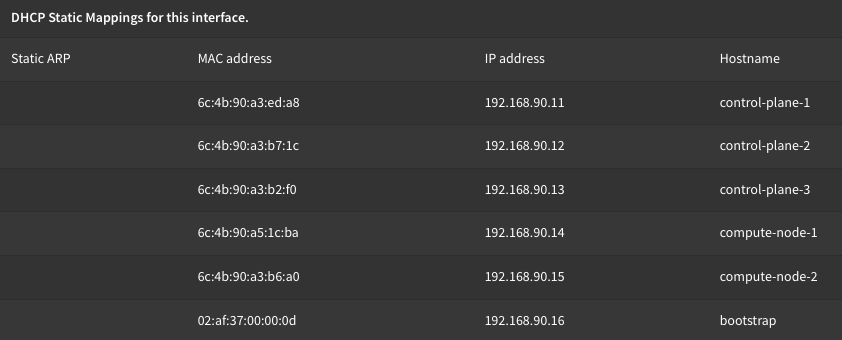
Now, back then the assisted installer wasn't a thing yet, and since there's no BMC on consumer hardware (these don't even have Intel vPro, for that you need the m9x0 series) so my only option was to go with UPI (user provisioned infrastructure) - which anyone who has deployed a UPI cluster can tell you is definitely hard mode. Logically, the process to deploy a UPI cluster isn't terribly different from doing an IPI cluster, but as its name implies, you have to do all the prerequisite configuration up front. When you deploy an IPI cluster, really all you need is a DHCP LAN segment, and you have to make sure you have DNS configured properly for your VIPs. With UPI on the other hand, you have to configure your DHCP server with MAC reservations, or configure static IPs on all your nodes - this is one of the main reasons why you'll see UPI deployments at customers who "don't trust DHCP". In my opinion, static DHCP reservations are a much cleaner way to go and they don't require any manual intervention on the nodes. Just set it once and forget it. In my lab, I use OPNsense for all things network. I used to be on pfSense but I switched sometime last year, and for the most part, just about everything was a 1:1 going between the two. You could of course use dhcpd or dnsmasq on any standard Linux server (or DHCP on a Windows server if you're into that kind of thing). Basically anything that can hand out addresses is fine. There are a couple of advanced DHCP configurations for PXE booting which we can dive into a little further on.
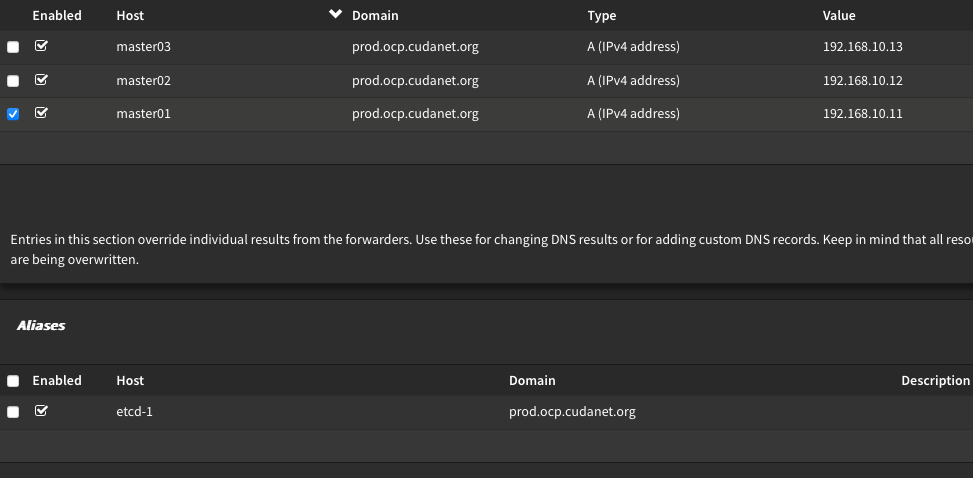
DNS
Configuring DNS for your nodes on a UPI cluster is a bit more involved than IPI. You have to create A records for all your nodes and your VIPs, the ingress must be a wildcard (eg; *.apps.cluster.domain), and you also have to create the necessary SRV records for etcd. If you're new to Openshift and Kubernetes, etcd is the transactional database which runs on the control plane nodes that stores all events in a kubernetes cluster. I use Unbound for DNS which is the default for OPNsense (and pfSense). Creating A Records and CNAMEs is pretty straightforward, but for creating the wildcards and SRV records needed by Openshift, you'll need to create one or more custom configs. These files reside in the directory /usr/local/etc/unbound.opnsense.d/ and are symlinked automatically to /var/unbound/etc/ after the unbound service is reloaded. Here's what the entries for my 'prod' cluster look like
server:
local-zone: "apps.prod.ocp.cudanet.org" redirect
local-data: "apps.prod.ocp.cudanet.org 86400 IN A 192.168.10.30"
local-data: "_etcd-server-ssl._tcp.prod.ocp.cudanet.org 86400 IN SRV 0 10 2380 etcd-1.prod.ocp.cudanet.org"
local-data: "_etcd-server-ssl._tcp.prod.ocp.cudanet.org 86400 IN SRV 0 10 2380 etcd-2.prod.ocp.cudanet.org"
local-data: "_etcd-server-ssl._tcp.prod.ocp.cudanet.org 86400 IN SRV 0 10 2380 etcd-3.prod.ocp.cudanet.org"The redirect stanza is the wildcard route for my ingress and the 3 SRV records at the bottom or required for etcd. The rest of the records required are just A Records and CNAMEs which can be created through the web UI. Note that each master node has a CNAME resolving to the corresponding SRV record above, eg; master01.prod.ocp.cudanet.org resolves to etcd-1.prod.ocp.cudanet.org
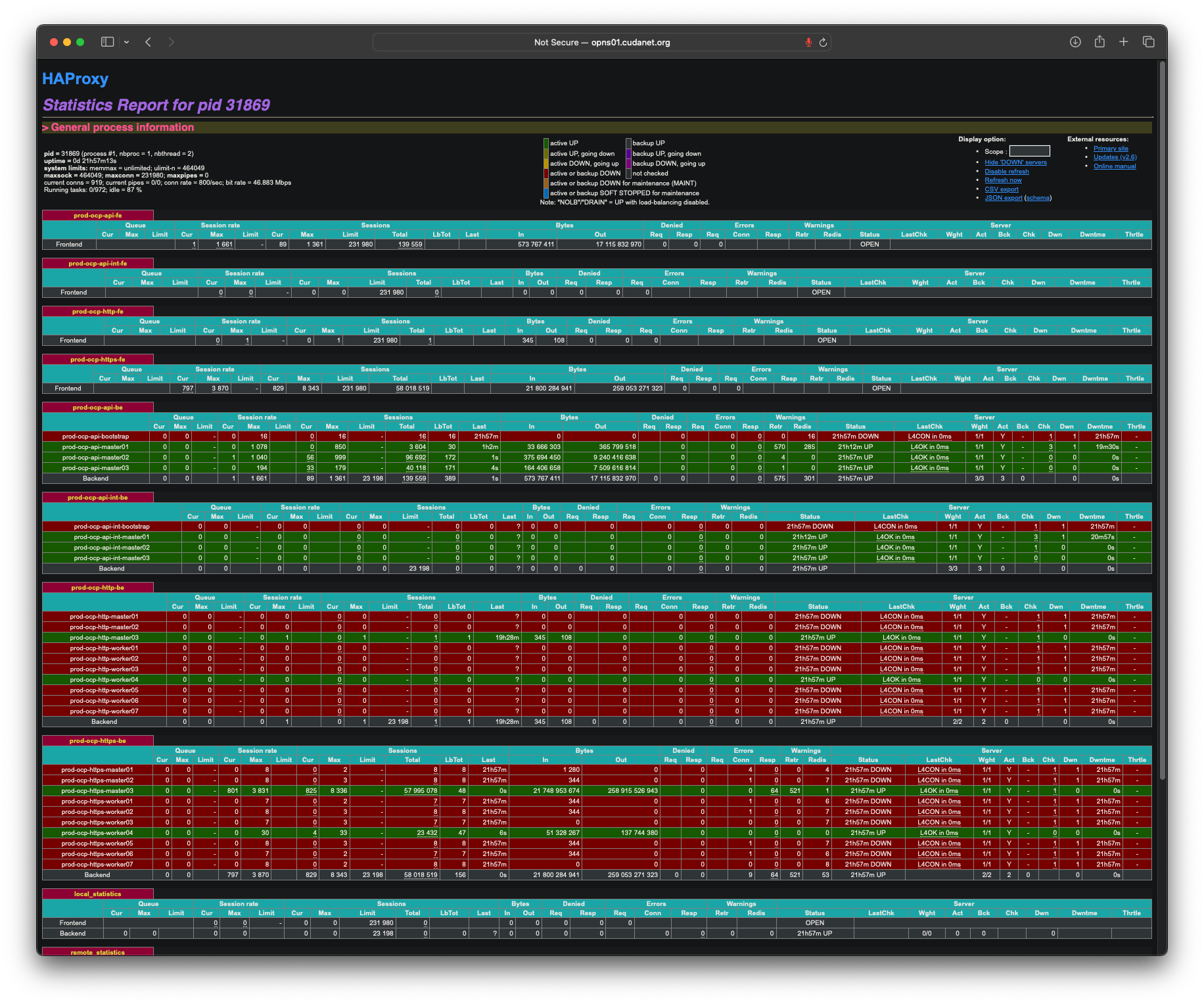
Load Balancing
Then you have to configure a handful of load balancers. Load balancing is probably the only really complicated piece you'll encounter coming from a traditional virtualization background. A load balancer consists of four parts - a backend, a frontend, a VIP and a healthcheck. A backend is a list of servers and ports you want to load balance between. A frontend specifies a port and protocol (eg; TCP) and is bound to a VIP. A VIP is a "Virtual IP". And finally, a healthcheck is configured to probe a service at a given interval for liveness. By default, Openshift uses HAProxy, but technically any load balancer will work. I've seen customers using F5 in front of Openshift. I've kicked around the idea of using nginx to handle load balancing. Basically you just need a thing that can round robin TCP ports.For a UPI cluster, Openshift needs four load balancers - one for the Kubernetes API, one for the machine config service (aka; internal API), and one each for HTTP and HTTPS for the ingress. Unlike an IPI cluster, these can actually all share the same VIP on a UPI cluster, but there are security reasons why you may need or want your ingress and API on separate VIPsThat's pretty much it - IP addressing, DNS and load balancing. Other than the load balancers, Openshift largely requires the same things as any other infrastructure platform like vSphere or Proxmox. Again, I use HAProxy on OPNsense, which is available as an installable package. There was a little bit of a learning curve to setting up HAProxy on OPNsense versus just running it from a config file, but thankfully the web UI is pretty logically organized and does syntax checking on the generated config to ensure that your settings are valid. For Openshift, the kubernetes API and the machine config service run on the control plane nodes, also called 'masters'. The ingress consists of both HTTP and HTTPS and runs on all schedulable nodes, aka; (workers, or schedulable masters).
Storage
Beyond that, the last thing you need is storage. Openshift is awesome, but it's not very useful without storage (or "persistence" as it's called in the container world). When you do an IPI deployment, you're typically going to have a default storage class configured (eg; the "thin" CSI driver on VMware). When you do UPI, (sometimes referred to as non-integrated deployment) you have to provide your own storage after the cluster has been deployed.
Every good home lab has some kind of NAS solution, whether it's an off the shelf box like a Synology or Qnap, or whether you go the DIY route and roll your own. TrueNAS is a pretty popular choice for DIY, but any storage solution with good CSI (container storage interface) drivers will do. TrueNAS, as well as Synology, can use Democratic CSI for iSCSI and NFS storage. If you don't have a NAS, there are a few other solutions available to you. There's TopoLVM (aka; LVM storage operator), hostpath provisioner and ODF. All three of which allow you to provision locally attached storage as PVCs, but both TopoLVM and HPP are limited to RWO (read/write once) storage classes, which may not be adequate for all workloads. ODF (Openshift Data Foundation) is an operator based on the upstream project, Rook that provides container-native storage. It can be deployed as hyperconverged storage (disk that exist on your nodes) or using an external Ceph cluster. Considering my lab used to run vSphere with vSAN, ODF seemed like a logical replacement. I've used both ODF as well as Rook. Other than ODF having a nice dashboard that incorporates directly into the web console, Rook works exactly like ODF because... well, they're both just Ceph under the hood. Ceph is great because it provides RWX (read/write many) storage classes for filesystem, block and object storage which means it can be used for all container workloads.
Compute
So we've covered two of the pillars that you need for a lab; networking and storage. The last one is compute - Openshift itself. If you do a UPI install of Openshift, there are a few different ways to bootstrap your nodes. You could burn the RHCOS installer to a thumb drive and manually apply the ignition files to the nodes one at a time, but that's tedious and can be kind of error prone. Although, for learning's sake I do recommend running through the process manually at least once so you can understand exactly what happens when you bootstrap a cluster. The way I do my deployment is to put all the artifacts needed on a PXE server, that way when I need to redeploy the cluster, all I have to do is upload the new ignition files, wipe the disks and reboot the nodes. Cluster comes up 20 minutes or so later like clockwork.
The process of bootstrapping a UPI Openshift cluster isn't terribly complicated, or all that different from an IPI install. Basically, for your control planes you need exactly 3 nodes with a minimum of 4 CPUs, 16GB of RAM and 120GB of locally attached storage. Given the fact that etcd is incredibly latency sensitive and write intensive, so you're going to need the fastest storage you can provide, NVMe preferably. Worker nodes require a minimum of 2 CPUs, 8GB of RAM and 120GB of storage, but the more resources you can throw at your compute nodes, the better. By default, when you deploy a UPI cluster, the control plane nodes are schedulable.
In broad strokes, to bootstrap a UPI cluster you need to generate an install config which is a YAML file that consists of the basic cluster configuration, your pull secret and optionally, an SSH key to access your nodes. here's an example:
apiVersion: v1
baseDomain: ocp.cudanet.org
compute:
- hyperthreading: Enabled
name: worker
replicas: 0
controlPlane:
hyperthreading: Enabled
name: master
replicas: 3
metadata:
name: prod
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
networkType: OVNKubernetes
serviceNetwork:
- 172.30.0.0/16
platform:
none: {}
fips: false
pullSecret: '{"auths":{...}}'
sshKey: 'ssh-rsa AAAA...3aW8U= [email protected]'
For a bare metal UPI cluster you specify replicas: 0 for the workers because unliked an IPI cluster, your workers do not consist of a machine set, so the process of adding new nodes is different. For control plane nodes, replicas: 3 is the only valid config. name: prod is the subdomain of the base domain that your cluster will use, in my case prod.ocp.cudanet.org. The network CIDRs are the default values, but just a word of caution - make absolutely certain they do not step on any existing networks. I worked at a company that used 172.30.0.0 for VPN (you're not supposed to since that's a reserved IP space) and it broke access to Openshift for remote workers, which became a huge problem during the pandemic.
You can get your pull secret from console.redhat.com under Containers > Downloads > Pull Secret. If you're deploying OKD (not Openshift) you can use the pull secret {"auths":{"fake":{"auth": "bar"}}}
While you're there, you're also going to need to grab the openshift-install and oc binaries.


Typically, I install these binaries to /usr/local/bin but anywhere in your path is fine. Some people prefer to have /home/user/bin directory.
Your SSH key should be located at ~/.ssh/id_rsa.pub. If you don't currently have one, you can generate one by entering the command ssh-keygen -t rsa.
Once you've created your install-config.yaml file, you're going to want to both create a backup of it as it gets deleted in the next step, and you're going to want to put it in it's own folder because the next step generates several new files and folders.
From the directory containing your install-config.yaml file, run the command openshift-install create manifests, which will create two folders named manifests and openshift, which contain a bunch of YAML files that will be used to create your Openshift cluster. At this time, any customizations you wish to provide , like descheduling your control plane nodes, disabling IPv6, etc. can do so now.
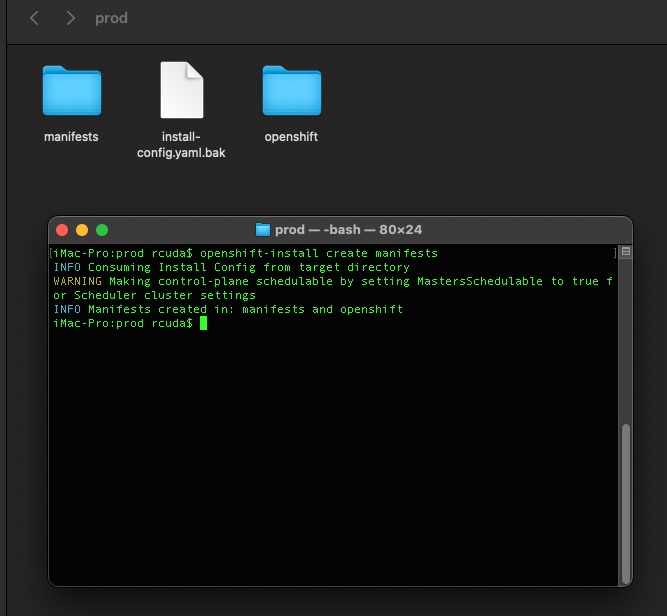
If you want to deschedule your control planes, edit the file manifests/cluster-scheduler-02-config.yml and change mastersSchedulable: true to mastersSchedulable: false. Don't worry, you can also change this later, just keep in mind that if you have schedulable control plane nodes, you need to make sure to add all three of them to both the HTTP and HTTPS backends on your load balancer.
Then once you've tweaked any necessary settings in your manifests, the next step is to generate the ignition files, which are essentially blobs of instructions that tell RHCOS how to install itself. From the same directory, run the command openshift-install create ignition-configs which will then generate three files, bootstrap.ign, master.ign and worker.ign.
The next part is a manual process. You're going to need to get the corresponding RHCOS ISO image for the particular version of OCP you're trying to install. Probably the easiest and surefire way to get the correct version is to run the command
openshift-install coreos print-stream-json | grep -H x86_64.iso
which should return a line like this
(standard input): "location": "https://rhcos.mirror.openshift.com/art/storage/prod/streams/4.13-9.2/builds/413.92.202307260246-0/x86_64/rhcos-413.92.202307260246-0-live.x86_64.iso",
If you wanted to get really fancy with it you could do something like wget $(openshift-install coreos print-stream-json | grep -H x86_64.iso | cut -d ':' -f 3,4 | sed 's/"//g' | sed 's/,//g' ) to download the ISO image in a one liner.
Once you've downloaded the ISO, you can burn it to a thumb drive with dd, Balena Etcher, Rufus, etc. Worth noting, if you're on macOS, you're going to need to convert the ISO to an IMG first, eg;
hdiutil convert -format UDRW -o rhcos-413.92.202307260246-0-live.x86_64.img rhcos-413.92.202307260246-0-live.x86_64.iso
mv rhcos-413.92.202307260246-0-live.x86_64.img.dmg rhcos-413.92.202307260246-0-live.x86_64.imgDon't ask me why... #AppleGonnaApp
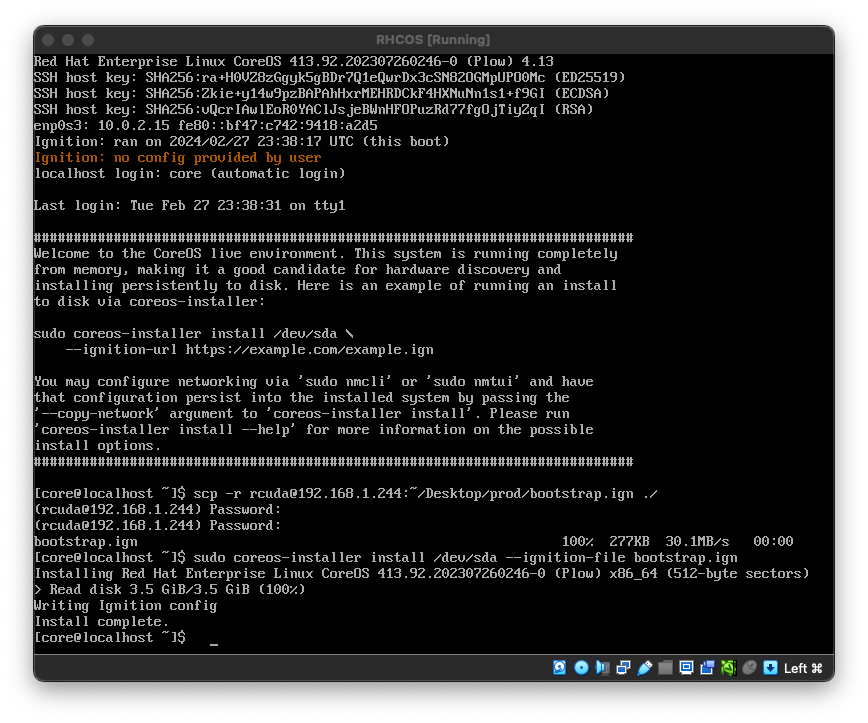
So, now with our bootable RHCOS thumb drive in hand, boot your nodes one at a time and copy the proper ignition file fore the node to the machine. There's probably about a dozen different ways to get the ignition file to the node, but the most straightforward way that doesn't require you to set anything else up is to just scp it over. Once booted into the RCHOS installer, copy the ignition file like this
scp -r [email protected]:~/Desktop/prod/bootstrap.ign ./
Then once the ignition file has been copied over, install CoreOS
sudo coreos-installer install /dev/sda --ignition-file bootstrap.ign
and then shut down the node once the install has completed.
nmcli and add the argument --copy-network to the install commandThen lather, rinse, repeat as needed for the rest of the nodes. Assuming you've gotten DHCP, DNS and load balancing set up correctly, the cluster should just come up on it's own once the nodes are rebooted and plugged into the network. In my lab, my nodes are completely headless and don't have any remote KVM capabilities, so it's imperative I get the prerequisites done right. It might take a little trial and error, but don't give up. I think it took me 5 tries to get my Openshift cluster up the first time I deployed UPI.
Once you've installed RHCOS on all your nodes, cabled them up and rebooted them (including the bootstrap! Don't forget your bootstrap node!), from the directory containing your ignition configs, run the command openshift-install wait-for bootstrap-complete which, barring any issues, should complete on it's own in 20 minutes or less. While this command doesn't actually do the install, it does provide you with status updates on where the cluster is at in the process. The first step is to bootstrap the cluster, which is when the bootstrap node brings up a single node instance of etcd and other cluster services, connects to the 3 master nodes, and then transfers etcd from the bootstrap node to the masters as a highly available and distributed instance. Once this is done, you should be able to see the kubernetes API and the machine config service as being up on all three masters on the HAProxy stats page I mentioned earlier. Once this is done you should safely be able to power off the bootstrap node.
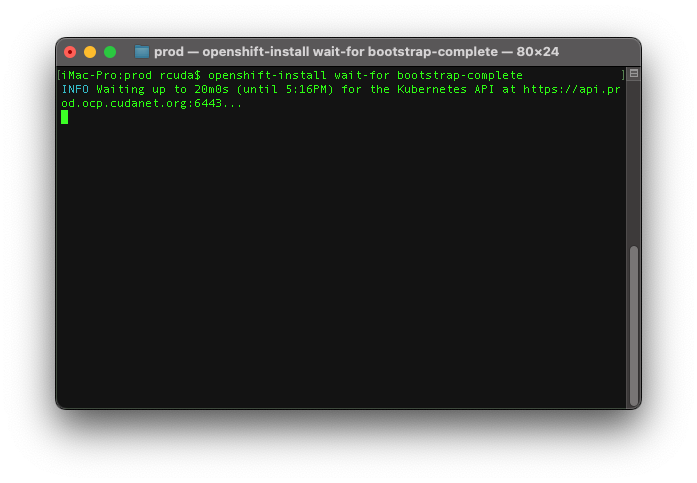
Then once bootstrapping the cluster is done, you can proceed with the next step. Run the command openshift-install wait-for install-complete, which by default has a 40 minute timeout. Depending on the speed of your network, compute and storage this can take less time or more. One thing to keep in mind - on a UPI install, you're going to need to periodically check for and sign any pending CSRs as your worker nodes join the cluster. There should be two CSRs per worker, so just make sure you get them all. If you don't sign them, and you've descheduled your masters, the ingress will never come up and the install will time out and eventually fail. You can sign them in batches with a loop like this
CSR=$(oc get csr --no-headers | grep -i pending | awk '{ print $1 }')
for c in $CSR;
do oc adm certificate approve $c;
doneBeyond that, it's really just a waiting game. If you've crossed all your t's and dotted all your i's within about a half hour, you should be looking at a shiny new Openshift cluster. You can check the status of your Openshift cluster with the command oc get co. Once all the cluster operators show Available as True and Progressing as False, you're cluster is officially done
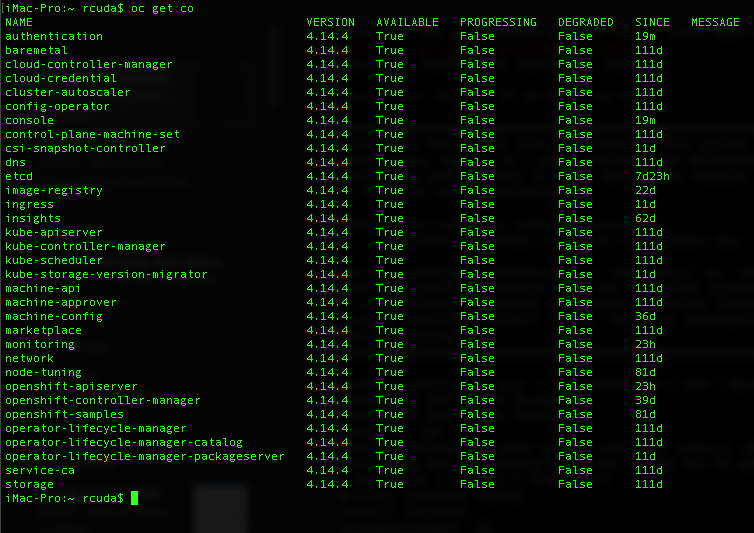
Then you can get into all the fun of day 2 ops like configuring CSI drivers for storage, replacing self signed SSL certs, configuring IDPs and RBAC, installing operators (not the least of which being Openshift Virtualization), etc.
Automation
Although I outlined the absolute most hands on (but fool proof) way to deploy an Openshift cluster, once you've run through the process a few times and you really start to understand how things work, you should probably consider automating some of these things. And no, I'm not talking about Ansible. I'm just talking about making the process of deploying the nodes a little less hands on. I use PXE boot to install RHCOS on my nodes, which requires a little extra work. I use my OPNsense router as "all things network" box, including PXE boot.
I've already written a very detailed explanation on how to set up PXE booting on OPNsense Just scroll down to the section labeled "PXE Boot:".
Long story short, you can use PXE to automate the process of installing RHCOS. Literally all I have to do to reimage is generate new ignition configs, upload the necessary boot artifacts to OPNsense, wipe the boot disks on my nodes and reboot them. Then like magic, the cluster just comes back up about 30 minutes later on the latest and greatest version of OCP