OKD for the Homelab


Honestly, this is not the blog article I wanted to write. I was hoping to be able to give OKD a resounding endorsement and be able to tell you, reader, how awesome and easy to use it is. Unfortunately, my experience in using OKD - for my intended goal, which I'll elaborate on a bit further - has not been without it's challenges and pitfalls. That being said, is OKD a viable platform for general consumption in a homelab? Yes, absolutely it is. However, in the interest of complete transparency, I must tell you that OKD is not a drop in replacement for Openshift. Sure, the two share a common code base and implement more or less the same core components, but I cannot stress enough that OKD is not "free" Openshift.
Perhaps the real value of Openshift lies in the extensive catalog of 1st party and certified 3rd party operators that make it incredibly easy to extend the functionality and features of Openshift in dramatic and powerful ways. By comparison, OKD has only a very small subset of community operators with many of them simply not having a free version. It's pretty hit or miss, for instance there is a community ArgoCD operator, but there isn't one for Openshift Pipelines (upstream Tekton).
My Goal
Initially, my goal was to evaluate whether OKD could be a viable, and perhaps more importantly -zero cost- alternative to VMware for use in a homelab setting with the intent to compete head-to-head with ProxMox. In a previous article, I touched on the Broadcom acquisition of VMware and the ripple effect that that has had throughout the IT world, from enterprises down to the home labs of the engineers who use their software. An alternative to VMware that has garnered a lot of praise recently is ProxMox VE. Compared to Openshift and OKD, ProxMox VE is actually a much more suitable alternative when doing a head to head comparison of vSphere features. Like vSphere, ProxMox is a traditional hypervisor platform. ProxMox also offers a lot of enterprise grade features that VMware offers only with a paid enterprise license; a central management console, clustering services, high availability, live migration, software defined storage, VM templating, snapshots, backup and restore, etc.
That is not to say that Openshift, or OKD are not capable of doing many (if not all) of those things as well. But it must be pointed out that Openshift is a container orchestration platform first, and it just happens to be capable of running VM workloads. With the average VMware refugee in mind, at least on paper, Proxmox seems like a much more logical choice. However, I would argue that increasingly, many people leverage virtualization primarily as a way to host container platforms first, and for managing VM workloads themselves second. In a homelab environment, often times people will go with whatever the path of least resistance is; "how do I spin up this app in as few steps as possible?". In a lot of cases, this might be something as simple as a Docker plugin included on their NAS, and for a non-production environment that is perfectly adequate.
It all really comes down to what the purpose of your homelab is and what you intend to accomplish with it. For some, the goal may simply be a way to host a few specific workloads. Things like Plex/Jellyfin, Minecraft servers and Nextcloud are some of the more common services you'll see homelabbers self hosting, and there are about a dozen different ways to deploy all of them ranging from a straightforward install on a VM to fully automated and managed application lifecycle on Kubernetes using CI/CD. Granted, running Openshift and using things like Tekton pipelines to build custom images and ArgoCD to do rollouts is really overkill if the goal is simply spin up a Plex server to share your movie collection with friends. Don't get me wrong, if that's all you're after then go with whatever works for you.
However, while my lab does host all of the apps mentioned above, the real function of my lab is for learning. I hone my craft as a containerization and app modernization expert in my home lab where if I make a change that ends up breaking things, it doesn't cause a production outage costing a company money. Usually the worst that ever happens for me is my Internet might go down for a couple of minutes, and while the other people in my house seem to have an unreasonable expectation of a five nines SLA for getting on Youtube and Fortnite, they're not the ones paying the bills, so if I need to make a change that makes something go boom, that's up to me. Honestly, the best way to learn new technology is by breaking it and learning either how to fix it, or how to prevent from breaking it again the same way.
The fact is, the world is moving towards containers, microservices and cloud-native development. At this point, if you're not using Kubernetes, you're behind the power curve, and Openshift is the premier container orchestration platform - for many reason. Openshift is the most consistent, robust, easy to use and fully platform agnostic container solution available, which means that standardizing on Openshift allows you to deploy your applications anywhere from public or private cloud, on-prem, virtual or bare metal, or at the edge without having to spend any time refactoring your applications. Not only that, but with CNV (Container Native Virtualization, aka; kubevirt), it allows you run your containers and virtual machines side by side on a single cohesive platform, both providing IT organizations with a cost effective hosting solution for VMs, and also opening the door to new ways of deploying legacy workloads, allowing you to modernize in place, giving you more runway to work with so you can start reducing technical debt incrementally without having to fully refactor legacy applications from the ground up.
Why Enterprise?
You may be asking yourself why you would want to go to all the trouble of deploying a container orchestration platform in your homelab if your end goal is simply to run a couple of VMs? Well, as I already pointed out - the world is moving away from VMs. Not that VMs are going away, just that they're the old way of doing things, and containers are the modern way to design and deploy applications. VMs still have their uses and always will. If all you want is to be able to run a couple of VMs to host some applications and something like ProxMox checks enough boxes for you, then more power to you. Have at it. However, as I also pointed out, I use my lab to learn skills that are valuable to my job and the fact of the matter is - there isn't a single IT organization out there using ProxMox for hosting any kind of production workloads. There just aren't. So to my mind, I wonder why anyone would waste time and effort to learn a platform that provides zero real world value. Anecdotally, I used to be Director of Infrastructure at my last job, and if I saw a resume cross my desk and a candidate even mentioned ProxMox, I'd assume they have no actual experience in IT. Yeah, that's gonna be a no from me, dawg...
I'm not trying to bag on ProxMox - it's a fine solution for what it is. I'm just saying it's not a serious enterprise platform, even though proponents of the project like to tout it's list of 'enterprise features'. In my opinion, if you're going to go to the trouble of building and running a home lab, it only makes sense to use real enterprise solutions that provide actual marketable skills and value. As we say in the military, "train like you fight, fight like you train". For a long time, the general recommendation for homelab was to just pony up the cash for VMUG Advantage membership which got you access for one year to licenses for most of the products in VMware's portfolio, and that made sense because up until very recently, VMware was the dominant on-prem hosting platform. I mean, they still are, but with the recent Broadcom acquisition, pretty much everyone is looking for an exit strategy. For some that might mean going all-in on the cloud. For others that might mean looking at other virtualization solutions like Nutanix. However, I would argue that no other platform is better poised to provide a migration path off of vSphere than Openshift. First and foremost, we are core-for-core substantially less expensive than VMware. Second, the fact is that many (if not most) companies running vSphere on-prem are running a container platform on top of it, and in terms of pure market share, that container platform is more often than not Openshift. So it makes sense to cut out the middle man, avoid paying the Broadcom tax and just going all-in on Openshift.
Free as in beer... and freedom
So where does OKD fit into this conversation, and what does Broadcom have to do with my homelab? Well... OKD is the upstream of Openshift, meaning it is for all intents and purposes the same bits as Openshift. Like Openshift, OKD is FOSS (free open source software). However, unlike Openshift, OKD comes with no support or warranty intended or implied and it lacks some of the value-add pieces that come included with a paid Openshift subscription, like some certified operators. But under the hood, OKD has the same engine that runs on Openshift and it comes with the low-low price of - free. Gratis. Zero dollars. OKD is not "freemium", it does not come with an eval period. It's just free, like ProxMox is. However, unlike ProxMox, OKD is for all intents and purposes functionally identical to Openshift. Any workload you can deploy on OKD can be deployed on Openshift and vice-versa using the exact same tooling and configuration without modification. Oh, and what I said about Container Native Virtualization on Openshift? Yeah, OKD has that too.
So what I'm saying is this; if you are currently running vSphere in your home lab and are looking for a replacement, I would urge you to at least take OKD for a spin to see if it might be a good fit. It's not going to cost you anything, and you might learn a few things along the way.
MVP
In the world of sports, an MVP is the "most valuable player". While I'd argue that my main OKD cluster is the most important thing I run in my lab, what MVP means in the IT world is "minimum viable product". Meaning, what features or functionality must it have in order to be considered usable. For Openshift/OKD to be a viable alternative to vSphere for a home lab, the list (for me) looks like this:
- container orchestration
- RWX block and file CSI drivers
- virtualization
- bridged network for virtualization
- loadbalancer services
With the exception of the plaform itself of coures, every one of these things is available as an operator in the Operator hub on Openshift. On OKD, some of those things are available as operators, others need to be configured manually.
Platform
Deploying OKD is not like a typical operating system install. You can't just boot up an ISO, follow a wizard and reboot to a functioning cluster. Deploying OKD is done generally by crafting an install-config.yaml, generating ignition configs, booting into the FCOS live installer and applying the appropriate ignition config for the node. There are 3 kinds of nodes - a control plane, a compute node and a bootstrap. Technically, there is a 4th kind of node called an infrastructure node, but they are essentially just unschedulable compute nodes designated for infrastructure services like storage workloads, and do not have any relevance for the process of bootstrapping a cluster.
You can grab the necessary OKD binaries here https://github.com/okd-project/okd/releases. I've noticed a few bugs in the web UI with OKD 4.15, so it might be best for now to stick with OKD 4.14. You'll need to download the appropriate openshift-client and openshift-install packages for your OS and architecture. Unpack the tar files and copy the binaries oc kubectl and openshift-install to somewhere in your $PATH. I usually put them in /usr/local/bin.
Once you've installed the binaries, you can download the appropriate boot files you'll need to deploy OKD on your nodes with the following command
openshift-install coreos print-stream-jsonThen scroll down until you see a section like this
"metal": {
"release": "38.20231002.3.1",
"formats": {
"4k.raw.xz": {
"disk": {
"location": "https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/38.20231002.3.1/x86_64/fedora-coreos-38.20231002.3.1-metal4k.x86_64.raw.xz",
"signature": "https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/38.20231002.3.1/x86_64/fedora-coreos-38.20231002.3.1-metal4k.x86_64.raw.xz.sig",
"sha256": "5d1250fbadefc9b787e45201a464825b62f2817b544be82adeddbc0b43c29339",
"uncompressed-sha256": "6597a3b7e9ae53d3a0af6b603f933e60a055af3abe90f93ec6679ebdc063c023"
}
},
"iso": {
"disk": {
"location": "https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/38.20231002.3.1/x86_64/fedora-coreos-38.20231002.3.1-live.x86_64.iso",
"signature": "https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/38.20231002.3.1/x86_64/fedora-coreos-38.20231002.3.1-live.x86_64.iso.sig",
"sha256": "d7839771d1810176f71e8b998d23d60eb580c941914264b5f5dec35798ac7503"
}
},
which gives you the URL of the live ISO you'll need (as well as the artifacts you'd need if you were to PXE boot your nodes). Download the ISO, eg;
wget https://builds.coreos.fedoraproject.org/prod/streams/stable/builds/38.20231002.3.1/x86_64/fedora-coreos-38.20231002.3.1-live.x86_64.isoFrom there, the process is relatively straightforward. Burn the ISO to a thumb drive, boot your nodes one at a time with the thumb drive, apply the appropriate ignition config and reboot. Then... you wait about 30 minutes.
I've outlined in much greater detail how to bootstrap a cluster here. The instructions are for regular OCP, however the process, and the networking prerequisites are identical.
Storage
I'm a big fan of Ceph storage for it's native integration with Kubernetes. I use ODF (Openshift Data Foundation) on my OCP clusters, which use an external Ceph cluster for storage. ODF can also be installed in such a way that it consumes local disks on your nodes to create a hyper-converged Ceph pool. Personally I don't like deploying ODF this way because it puts all your eggs in one basket, and if your Openshift cluster becomes unrecoverable, so does all your data. It's worth pointing out that ODF in either configuration is only available as an add-on to Openshift (either as part of Openshift Platform Plus, or ODF/ODF Advanced which are separate paid products). ODF is installed as an operator.
On OKD, you can use Rook (https://rook.io), the upstream project of ODF. Rook is not available through the operator hub, so you'll have to install it manually. You'll need to determine ahead of time whether you're deploying rook in internal (hyperconverged mode) or external (using a dedicated Ceph cluster) mode. I'm not going to cover deploying rook internal but the process is largely the same.
First you need to gather some information from your Ceph cluster.
# on the external Ceph cluster
ceph health
ceph fsid
ceph auth get-key client.admin
#output should be something like this
HEALTH_OK
86bf38ca-7f3d-11ee-a2d8-02cc0f00000b
AQBTP01l4nMEJxAAceVBUNVoAxUr+ZQgcAT6hA==
# Then you need to use the IP address of the primary MON node.
# export the proper values as aliases
# on your workstation
export NAMESPACE=rook-ceph
export ROOK_EXTERNAL_FSID=86bf38ca-7f3d-11ee-a2d8-02cc0f00000b
export ROOK_EXTERNAL_ADMIN_SECRET=AQBTP01l4nMEJxAAceVBUNVoAxUr+ZQgcAT6hA==
export ROOK_EXTERNAL_CEPH_MON_DATA=a=192.168.20.41:3300
# clone the rook git repo
git clone https://github.com/rook/rook.git
# create the rook namespace
oc new-project rook-ceph
# create a service account with anyuid privs for rook to use
oc create serviceaccount rook-ceph-system -n rook-ceph
oc adm policy add-scc-to-user anyuid -z rook-ceph-system -n rook-ceph
# apply the appropriate yaml files
oc apply -f rook/deploy/examples/crds.yaml
oc apply -f rook/deploy/examples/common.yaml
oc apply -f rook/deploy/examples/operator.yaml
# wait for the operator pods to spin up
oc apply -f rook/deploy/examples/operator-openshift.yaml
# rename some references to rook-ceph-external
sed -i "s/rook-ceph-external/rook-ceph/g" rook/deploy/examples/common-external.yaml
oc apply -f rook/deploy/examples/common-external.yaml
# rename some references to rook-ceph-external
sed -i "s/rook-ceph-external/rook-ceph/g" rook/deploy/examples/import-external-cluster.sh
sh rook/deploy/examples/import-external-cluster.shThen you need to edit a secret
oc edit secret rook-ceph-mon -n rook-ceph
and delete these two lines
ceph-secret: ""
ceph-username: ""# rename some references to rook-ceph-eternal
sed -i ’s/rook-ceph-external/rook-ceph/g’ rook/deploy/examples/cluster-external.yaml
oc apply -f rook/deploy/examples/cluster-external.yaml
#wait until all the pods come up, which will probably take a few minutes. you can monitor the status with this command
oc get pod -n rook-ceph
# you can check the status of your ceph cluster with this command
watch -n5 oc get CephCluster --all-namespaces
# once it says status is connected you can create your storage classes
NAMESPACE NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL FSID
rook-ceph rook-ceph 4h14m Connected Cluster connected successfully HEALTH_OK true 86bf38ca-7f3d-11ee-a2d8-02cc0f00000bExample Ceph RBD storage class:
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
requireSafeReplicaSize: true
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephrbd
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: rbd-prod
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: ext4
mounter: rbd
mapOptions: "krbd:rxbounce"
allowVolumeExpansion: true
reclaimPolicy: DeleteExample Ceph FS storage class:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
provisioner: rook-ceph.cephfs.csi.ceph.com
parameters:
clusterID: rook-ceph
fsName: cephfs-prod
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-cephl # namespace:cluster
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:#set rook-cephrbd as your default storage class
oc annotate storageclass rook-cephrbd "storageclass.kubernetes.io/is-default-class=true"
# create snapshot classes
oc apply -f rook/deploy/examples/csi/cephfs/snapshotclass.yaml
oc apply -f rook/deploy/examples/csi/rbd/snapshotclass.yamlTest to make sure you can create PVCs
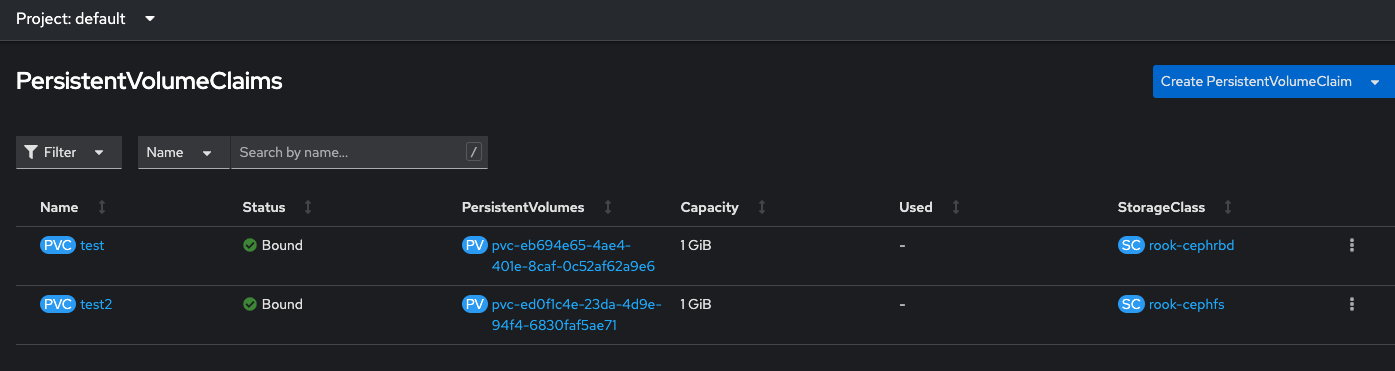
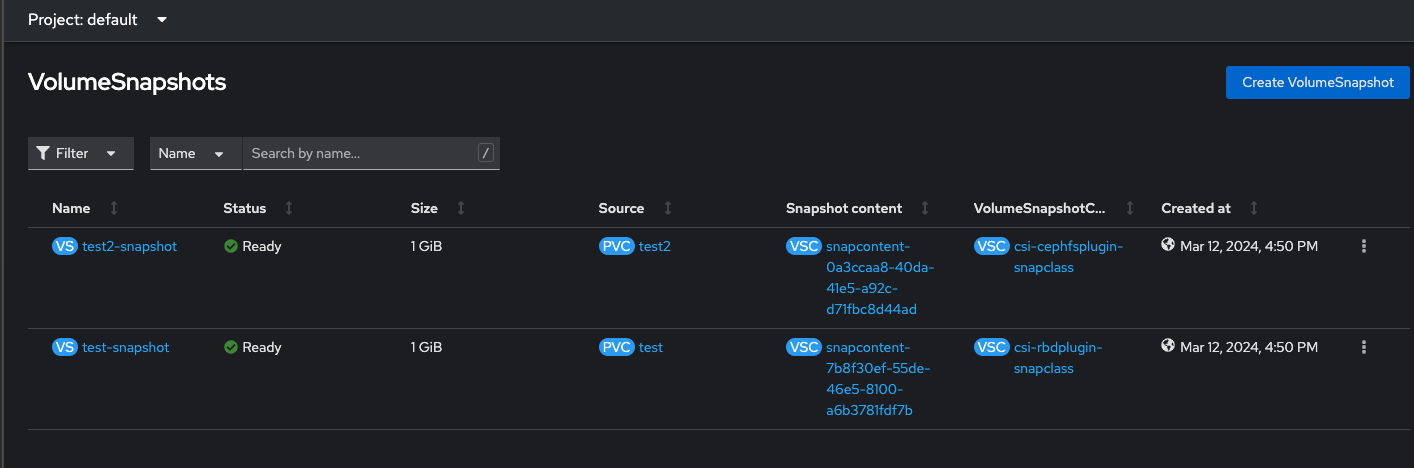
and while we're at it, let's make sure we can take snapshots too
Virtualization
Thankfully, it's very easy to deploy OKD's hypervisor called kubevirt. It is deployed as an operator and the install is very straightforward. The only prerequisite is that you need to have a RWX block storage class set as your cluster default storage class (which we did in the previous step). Worth noting - if you use ceph-rbd as your default storage class for kubevirt, you must have the following two parameters specified in your storage class (the examples provided by rook don't):
mounter: rbd
mapOptions: "krbd:rxbounce"Otherwise, you'll have alerts on the console that won't go away.
While logged in to the web UI as cluster admin, navigate to the Operator hub and search for kubevirt
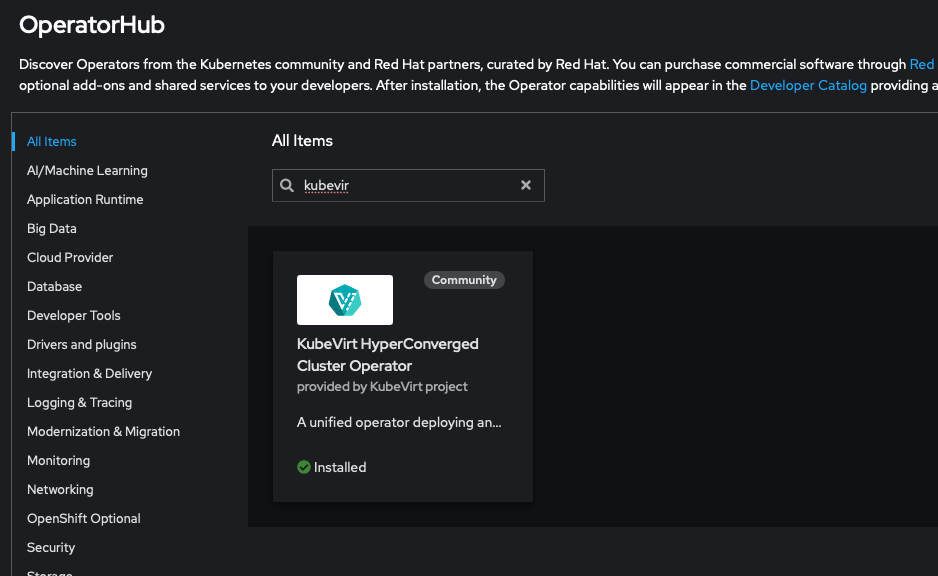
Install the operater, which will take a few minutes. Once it's installed, create a hyperconverged instance
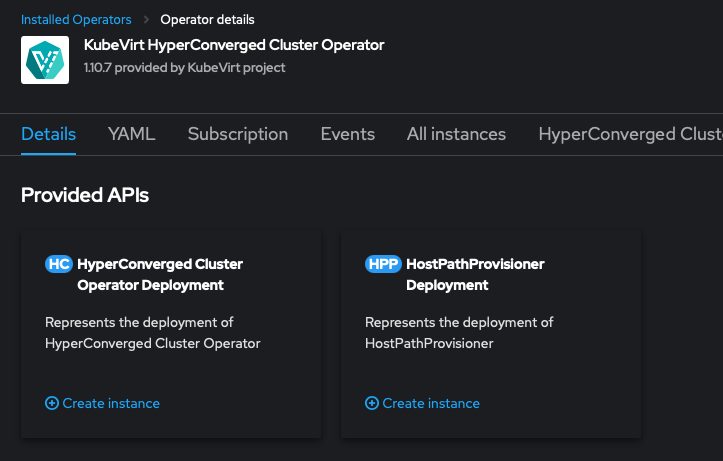
You can simply accept the default values. The defaults are sensible and can be changed after the fact if needed. It's going to spin up a couple dozen pods and create some PVCs which will be used to create the boot sources for some of the VM templates (CentOS 7-9 and Fedora latest).
That's all there is to deploying the kubvirt operator.
Bridged Networking
Bridged networking is what every traditional virtualization platform uses to provide connectivity to VMs. VLANs are trunked into the hypervisor, a bridge interface is created, VM is attached to the bridge and gets an IP on the appropriate VLAN. By default, kubevirt does not provide this capability, probably because there's almost no way the upstream project could implement a solution that fits every single use case. However, Openshift, and by extension OKD, have only ever had two options, OpenshiftSDN and OVN-k, and one of them is deprecated and will eventually go away, so effectively the only network stack available on OKD is OVN-k. Thankfully, adding the functionality to kubevirt is easy. You'll need to install the kubernetes nmstate operater, which unfortunately on OKD is not available on the Operator hub.
You can deploy nmstate on your OKD cluster in one shot with the following commands
oc apply -f https://github.com/nmstate/kubernetes-nmstate/releases/download/v0.81.0/nmstate.io_nmstates.yaml
oc apply -f https://github.com/nmstate/kubernetes-nmstate/releases/download/v0.81.0/namespace.yaml
oc apply -f https://github.com/nmstate/kubernetes-nmstate/releases/download/v0.81.0/service_account.yaml
oc apply -f https://github.com/nmstate/kubernetes-nmstate/releases/download/v0.81.0/role.yaml
oc apply -f https://github.com/nmstate/kubernetes-nmstate/releases/download/v0.81.0/role_binding.yaml
oc apply -f https://github.com/nmstate/kubernetes-nmstate/releases/download/v0.81.0/operator.yaml
cat <<EOF | oc create -f -
apiVersion: nmstate.io/v1
kind: NMState
metadata:
name: nmstate
EOF
Once installed, you will be able to create a couple new kinds of CRs, most importantly - NodeNetworkConfigurationPolicies, or nncp
In a nutshell, the way that bridge networking works on OKD with OVN-k is you create a bridge that is tagged with a VLAN, and then you attach VMs to that bridge without specifying the VLAN tag, effectively inheriting the 802.11Q tag from the bridge interface. It sounds more complicated than it really is, but here's an example. Let's use VLAN20 where enp0s31f6 is the name of the physical NIC on the nodes
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: worker-vlan20-bridge-policy
spec:
nodeSelector:
node-role.kubernetes.io/worker: ''
desiredState:
interfaces:
- name: vlan20
state: up
type: vlan
ipv4:
enabled: false
ipv6:
enabled: false
vlan:
base-iface: enp0s31f6
id: 20
- name: br20
description: bridge for vlan20
type: linux-bridge
state: up
ipv4:
enabled: false
ipv6:
enabled: false
bridge:
options:
stp:
enabled: false
port:
- name: vlan20
Then once you've created one or more nncp, you can create a NetworkAttachmentDefinition. These are namespaced CRs and can be created easily through the web UI. Here's an example using VLAN20. You just have to specify the name of the bridge interface, in this case br20 which was defined in the nncp we just created
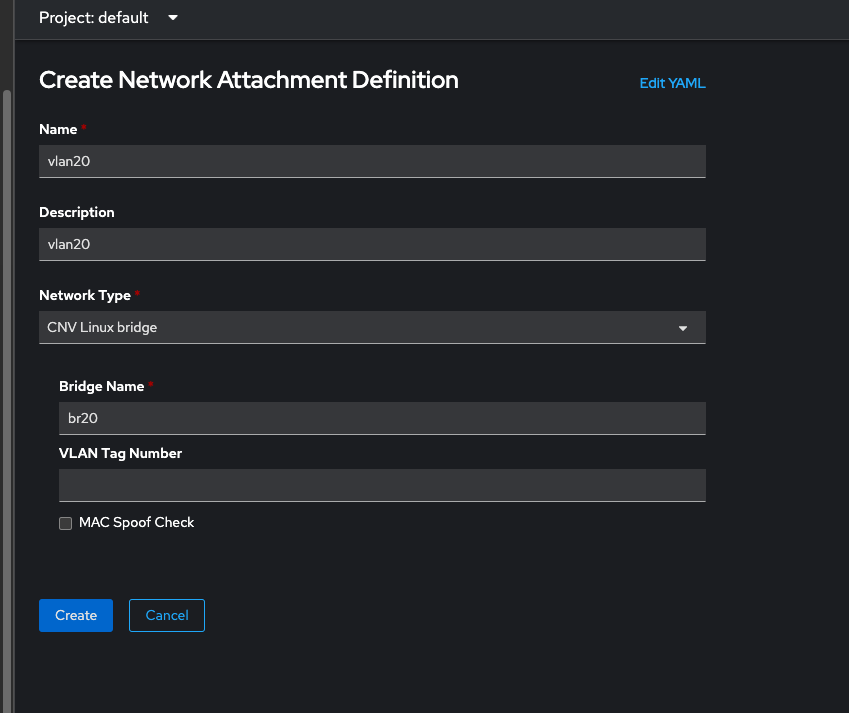
and for good measure, here's the yaml
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
annotations:
description: vlan20
k8s.v1.cni.cncf.io/resourceName: bridge.network.kubevirt.io/br20
name: vlan20
namespace: default
spec:
config: '{"name":"vlan20","type":"cnv-bridge","cniVersion":"0.3.1","bridge":"br20","macspoofchk":false,"ipam":{},"preserveDefaultVlan":false}'
So now let's create a VM to test our bridge. Navigate to Virtualization > create Virtual Machine > From Template and select Fedora.
Navigate to customize > configure > Network and configure the default interface to use the network default/vlan20 we just created with Bridge as the type
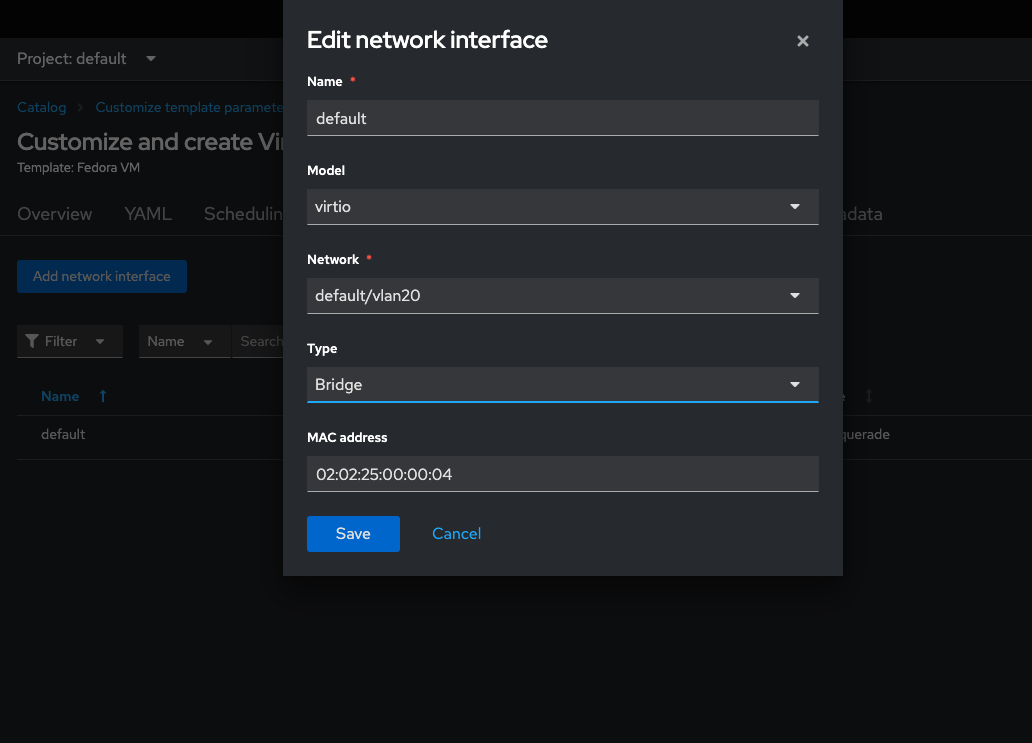
Click save, and create the virtual machine. It will provision the machine and boot up shortly - on my cluster this took less than a minute. Once the VM is booted qemu guest agent service should report the IP address in the console
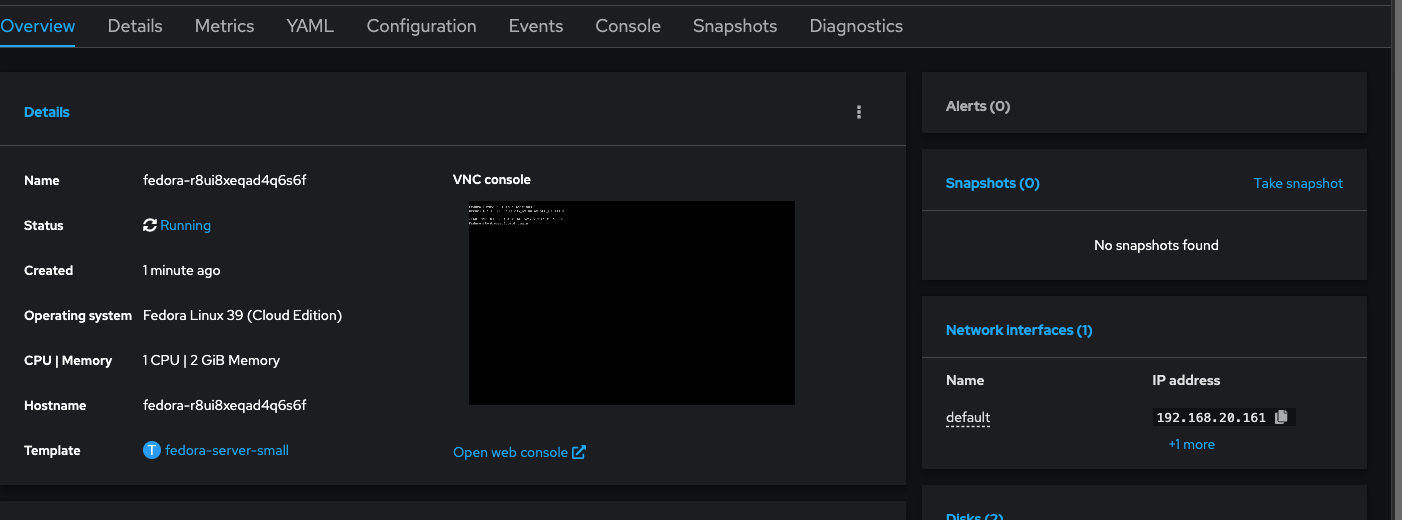
Now let's try pinging it
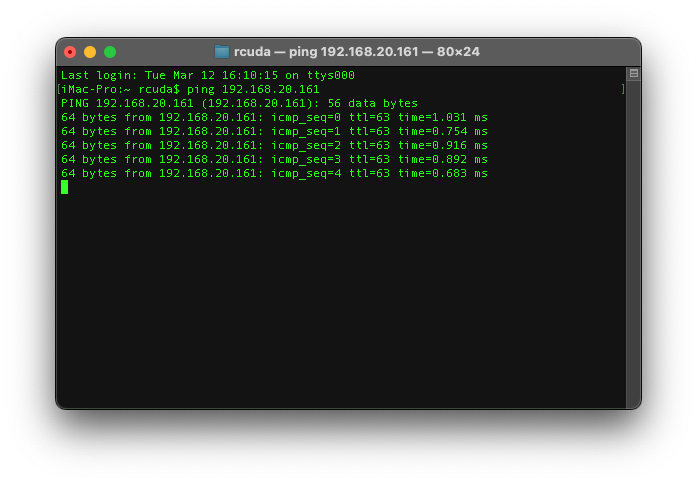
Success!
Load Balancers
Now, this is one of the places where I actually struggled with OKD, but to be fair, for the first several years I was running Openshift, I had similar problems. In the cloud, a load balancer service is generated and can use the cloud APIs to grab an IP address out of a pool that you've already paid for. On prem, load balancers are a little more difficult. In the past, as a dirty hack/workaround, I would set a load balancer service external IP address to the ingress or API VIP of my Openshift cluster. It works in a pinch, but it's not the best idea, and quickly becomes a problem when we're talking about using services on a VM which are common to Openshift, eg; HTTP/HTTPS and SSH, ports 80, 443 and 22 respectively.
This is where MetalLB comes in. On Openshift, MetalLB is available as an operator. It's super easy to set up and use, you just install the operator, create an IPAddressPool and you're off to the races. However, on OKD there is no community MetalLB operator, and trying to deploy it from the official git repo, either using static manifests or as an operator fails with all kinds of problems.
With a little help from a colleague and a little bit of hacking on it, I was finally able to get MetalLB deployed on OKD. Shout out to Ken Moine who shared his (mostly) working kustomize with me. Granted it's targeted at vanilla k8s on Fedora, so it took some extra work to get it running on OKD
oc create ns metallb-system
&
oc apply -n metallb-system -k https://raw.githubusercontent.com/kenmoini/ansible-fedora-k8s/main/cluster-config/install-metallb/operator/kustomization.ymlWhich pulls in everything for you and creates among other things, 2 service accounts, a deployment and daemonset, all of which have to be kicked around a little bit to get them to play nice with OKD. Basically I had to set the securityContext on both the ds and the deployment to privileged: true and then patch the service accounts, speaker and controller with privileged SCC. Not the best idea from a security standpoint and definitely not OKD friendly, but hey... it works.
oc create serviceaccount speaker -n metallb-system
oc adm policy add-scc-to-user anyuid -z speaker
oc adm policy add-scc-to-user privileged -z speaker
oc adm policy add-scc-to-user hostaccess -z speaker
oc create serviceaccount controller -n metallb-system
oc adm policy add-scc-to-user anyuid -z controller
oc adm policy add-scc-to-user privileged -z controller
oc adm policy add-scc-to-user hostaccess -z controllercontroller deployment yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
labels:
app: metallb
component: controller
name: controller
namespace: metallb-system
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 3
selector:
matchLabels:
app: metallb
component: controller
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
prometheus.io/port: "7472"
prometheus.io/scrape: "true"
creationTimestamp: null
labels:
app: metallb
component: controller
spec:
containers:
- args:
- --port=7472
- --log-level=info
env:
- name: METALLB_ML_SECRET_NAME
value: memberlist
- name: METALLB_DEPLOYMENT
value: controller
image: quay.io/metallb/controller:v0.13.12
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: monitoring
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: controller
ports:
- containerPort: 7472
name: monitoring
protocol: TCP
- containerPort: 9443
name: webhook-server
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: monitoring
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /tmp/k8s-webhook-server/serving-certs
name: cert
readOnly: true
dnsPolicy: ClusterFirst
nodeSelector:
kubernetes.io/os: linux
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: controller
serviceAccountName: controller
terminationGracePeriodSeconds: 0
volumes:
- name: cert
secret:
defaultMode: 420
secretName: webhook-server-certspeaker daemonset yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
annotations:
labels:
app: metallb
component: speaker
name: speaker
namespace: metallb-system
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: metallb
component: speaker
template:
metadata:
annotations:
prometheus.io/port: "7472"
prometheus.io/scrape: "true"
creationTimestamp: null
labels:
app: metallb
component: speaker
spec:
containers:
- args:
- --port=7472
- --log-level=info
env:
- name: METALLB_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: METALLB_HOST
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
- name: METALLB_ML_BIND_ADDR
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: METALLB_ML_LABELS
value: app=metallb,component=speaker
- name: METALLB_ML_SECRET_KEY_PATH
value: /etc/ml_secret_key
image: quay.io/metallb/speaker:v0.13.12
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: monitoring
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: speaker
ports:
- containerPort: 7472
hostPort: 7472
name: monitoring
protocol: TCP
- containerPort: 7946
hostPort: 7946
name: memberlist-tcp
protocol: TCP
- containerPort: 7946
hostPort: 7946
name: memberlist-udp
protocol: UDP
readinessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: monitoring
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/ml_secret_key
name: memberlist
readOnly: true
- mountPath: /etc/metallb
name: metallb-excludel2
readOnly: true
dnsPolicy: ClusterFirst
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: speaker
serviceAccountName: speaker
terminationGracePeriodSeconds: 2
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
operator: Exists
volumes:
- name: memberlist
secret:
defaultMode: 420
secretName: memberlist
- configMap:
defaultMode: 256
name: metallb-excludel2
name: metallb-excludel2
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdateEventually, I'll clean all this up and turn it into something that can be applied with a one liner with regular yaml files and not have to fiddle with things.
Once all the pods were up (there will be one controller pod and one speaker per node) you can create an IPAddressPool
iMac-Pro:metallb rcuda$ oc get pod
NAME READY STATUS RESTARTS AGE
controller-569cd88bcf-jll7s 1/1 Running 0 4h16m
speaker-4hrlv 1/1 Running 0 4h45m
speaker-5sr45 1/1 Running 0 4h45m
speaker-b2c4t 1/1 Running 0 4h45m
speaker-b6pnr 1/1 Running 0 4h45m
speaker-n7xp4 1/1 Running 0 4h45m
speaker-q9fxc 1/1 Running 0 4h45m
speaker-ql8wt 1/1 Running 0 4h45m
speaker-rh6tc 1/1 Running 0 4h45m
speaker-s7kxx 1/1 Running 0 4h45m
speaker-x5zlr 1/1 Running 0 4h45mIPAddressPool yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: okd-201-250
namespace: metallb-system
spec:
addresses:
- 192.168.10.201-192.168.10.250
autoAssign: true
avoidBuggyIPs: falseAnd now we can try and create a load balancer service. I spun up another VM and exposed SSH as a service to test it out.
You can quickly create services from VMs using virtctl. virtctl can be downloaded from the Web console. Just click the ? icon next to the username up in the top right corner and select Command Line Tools from the drop down. Then download the appropriate binary for your OS and architecture

I usually put mine in /usr/local/bin/ but anywhere in you $PATH is fine.
Expose a port on a VM as a service with a command like this
virtctl expose vm fedora-0n32r6e4cc80kwox --port=22 --type=LoadBalancer --name=fedora-0n32r6e4cc80kwoxwhich will create a load balancer service with the same name as the VM exposing port 22 (SSH).
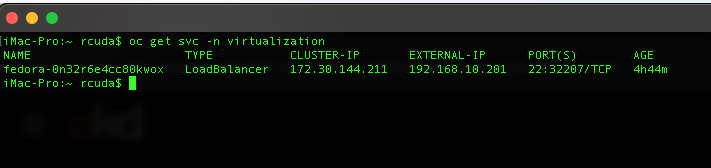
We can see it created a service with the external IP of 192.168.10.201, so lets try to connect to it
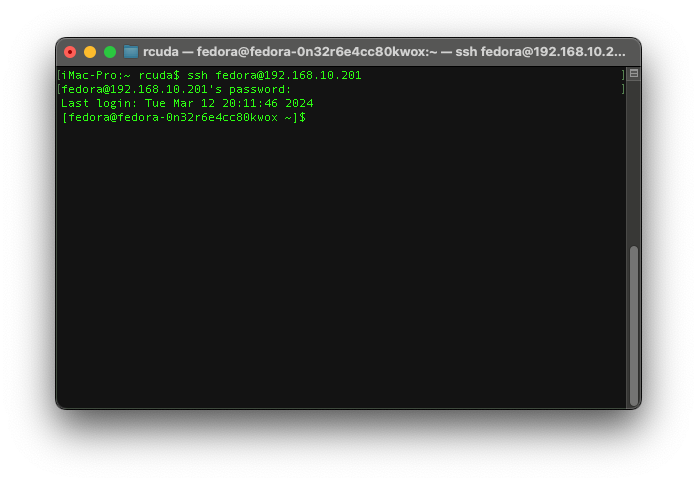
Success!
Wrapping up
We've covered quite a few things thus far; deploying OKD, and configuring the addon services that I consider necessary for it to be a viable platform for general use in a home lab. Granted, there are still tons of other features that we could discuss like backup/restore (there's an operator for that called OADP), live migration (it works out of the box), high availability (there's an operator for that called Node Health Check) and CI/CD pipelines (it's a little more complicated), and some nice to haves like managing SSL certs (there's an operator for that called Cert Manager) or LDAP auth for user access and RBAC (you just need to configure an ID Provider). None of those are really within the scope of this article, I really wanted to limit my focus to what I consider MVP for a lab. In the end, I've got to say that as long as you're willing to forego some of the creature comforts of downstream Openshift and it's extensive Operator catalog and you're willing to get your hands dirty configuring some things manually, OKD is pretty damn good. If we're being honest, it's a hell of a lot better than trying to roll your own vanilla Kubernetes cluster and bolt on all the functionality that OKD provides. Ultimately, as a zero cost alternative to ProxMox, I'd argue that while admittedly a lot more complex, learning and working with a leading industry standard platform is just better, and having a strong community of tinkerers using OKD is only going to help make it even better.