Migrating from Unbound to DNSMasq


(AKA; I'm sick of all these damned caching issues)
I've been using unbound as my DNS server for about as long as I can remember. It has served me well. It's easy to use, and up until recently it has worked well enough. Until it didn't...
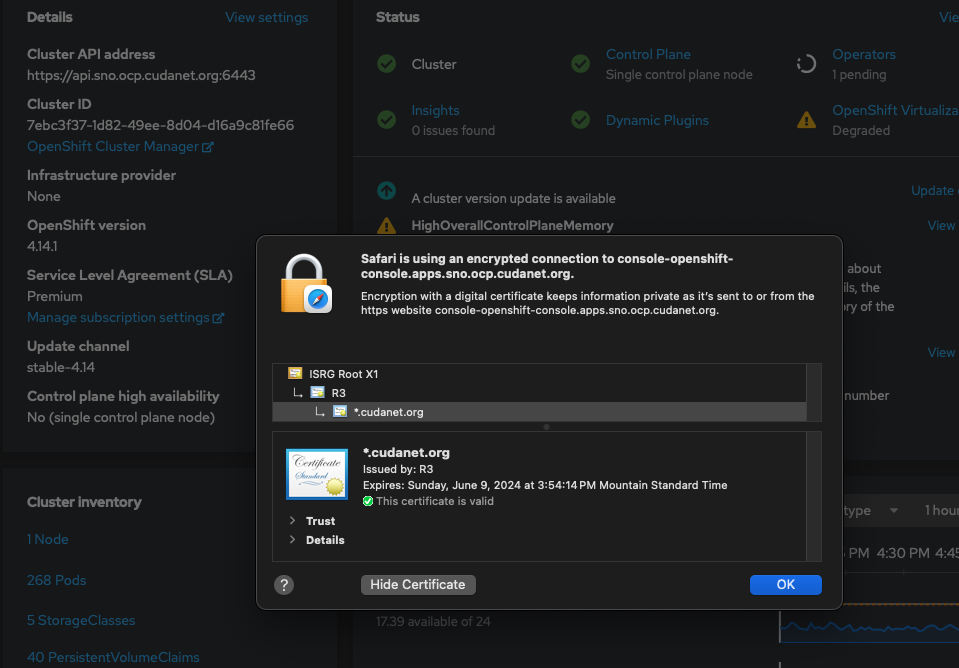
I'm actually not sure when the problems started. First there were some issues while getting on OpenVPN for work. Then I started running into some weirdness with things in my lab not loading properly and having to spend a whole lot of time opening incognito tabs and clearing caches just to get to things like my router or my Openshift clusters. It doesn't help that each browser seems to handle things like caching and SSL validity differently. I'm a Mac user and Safari is my main browser, but it has gotten extremely picky lately about how it handles SSL, basically refusing to allow you to visit any site that doesn't have a proper externally signed and trusted SSL cert. I gave up on the idea of managing an internal CA years ago because of the sheer number of headaches it caused and just went all in on Letsencrypt.
Don't get me wrong, I love letsencrypt. It provides an invaluable service to the Internet, but it's not without it's problems - namely the 90 day expiry of certs. I get that old SSL standards like certs being valid for like 100 years was probably not the best idea in the world, but I do think that 90 days is a bit much. I think a sensible middle ground would be a year, and there are definitely some paid certificate authorities that will allow you to provision certs valid for a year (although your mileage may vary as to whether your browser is going to trust that cert). But as they say, beggars can't be choosers, so I have to work with what I've got, and that means rotating certs every 90 days or less. I don't like having to maintain lots of different certs, so up until recently I typically would just generate one wildcard cert for my whole domain with appropriate SANs for subdomains (like my individual Openshift clusters) and just rotate manually as needed. As long as I'm proactive about it and rotate certs prior to their expiry, I don't have any issues. However, I've been really busy lately with work and life and something trivial like "when does my wildcard cert expire?" kind of slipped my mind. Fast forward to last Friday when it expired and let's just say all hell broke loose in my lab. Storage was broken. My git repos were down, as was my container registry. My Openshift clusters were inaccessible. LDAP wasn't working. I couldn't even get to the web UI of my router. It was not fun, to say the least. After a couple of hours of fiddling with things, I was finally able to restore enough functionality to my lab that I was able to get back into things.
We have an app for that!
It dawned on me that I really needed to automate the process of rotating my certs. We have an app for that! (or rather, an operator). The cert manager operator for Openshift became generally available as of May of last year, but I've never been able to successfully use it. I had taken a look at it before. I tried spinning it up and getting it to request certs but it would always just get stuck with pending certs waiting to be approved and never actually created, so I bailed on the idea and just said "this is a project for another day". Well, that day happened to be last Friday when my entire lab blew up and forced my hand.
So I went back and revisited the cert-manager operator. Deploying the operator itself is simple, you just search on the Operator hub for cert-manager and install it. There are two versions of the operator available, the certified Red Hat version and the community version. I chose to use the official Red Hat version.
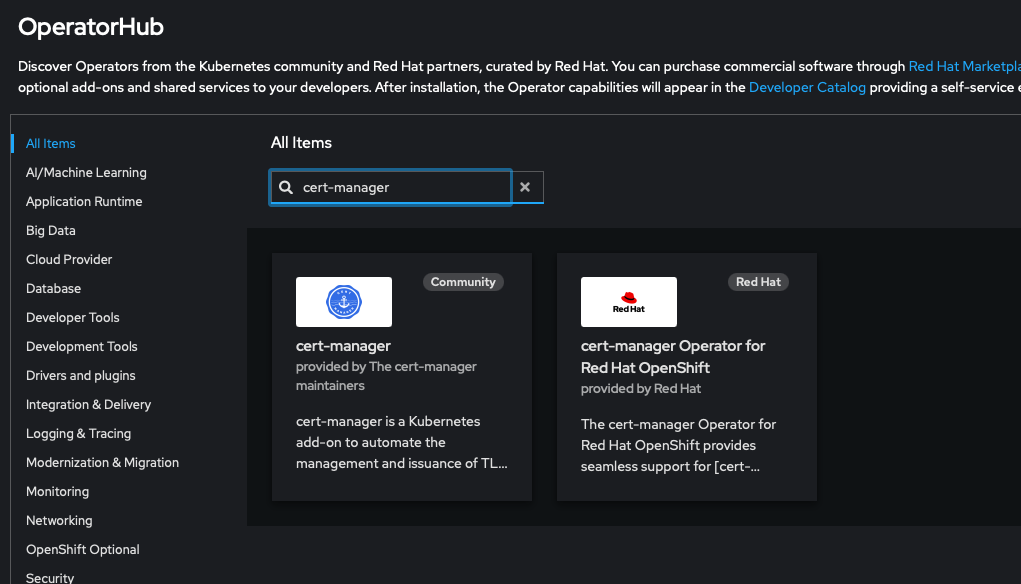
Once installed you need to configure a couple of things. First, your cert-manager instance is going to need to be able to authenticate to your DNS provider's API, in my case this is Cloudflare, which are one of the officially supported providers. The instructions for generating an API key or token will vary from provider to provider, but basically you'll just create one or more secrets like this
apiVersion: v1
kind: Secret
metadata:
name: cloudflare-api-token-secret
type: Opaque
stringData:
api-token: bm90IGEgcmVhbCBBUEkgdG9rZW4K
---
apiVersion: v1
kind: Secret
metadata:
name: cloudflare-api-key-secret
type: Opaque
stringData:
api-key: bm90IGEgcmVhbCBBUEkga2V5Cg==
Then you need to generate an issuer . An issuer can be either a ClusterIssuer which as it's name might imply is available cluster wide, or an Issuer which will be a namespaced CR. There are two solvers for issuers, either http01 or dns01. The mechanism that http01 uses is to create a clusterIP service with the challenge string which should be externally accessible/resolvable. However, this requires port 80 (unencrypted HTTP) to be available from your cluster externally, and my ISP - like many - blocks port 80. So my only option is to use dns01 as my solver. The way dns01 works is more or less the same as http01 except it creates a temporary TXT record on your external DNS containing the challenge key.
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt
annotations:
namespace: cert-manager
spec:
acme:
email: [email protected]
server: https://acme-v02.api.letsencrypt.org/directory
privateKeySecretRef:
name: acme-key
solvers:
- selector:
dnsZones:
- 'cudanet.org'
dns01:
cnameStrategy: Follow
cloudflare:
email: [email protected]
apiKeySecretRef:
name: cloudflare-api-key-secret
key: api-key
# apiTokenSecretRef:
# name: cloudflare-api-token-secret
# key: api-tokenand now, assuming your cluster is accessible from the internet and you have created the appropriate CNAME or A records on your external DNS provider, you can request a certificate. Here is the example I used for infra cluster's ingress. Worth noting, the values for duration and renewal are important. Letsencrypt certs are valid for 90 days, and I rotate my cert 15 days before it expires.
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: letsencrypt
namespace: openshift-ingress
spec:
secretName: letsencrypt
secretTemplate:
duration: 2160h0m0s # 90d
renewBefore: 360h0m0s # 15d
commonName: '*.apps.infra.ocp.cudanet.org'
usages:
- server auth
- client auth
dnsNames:
- '*.apps.infra.ocp.cudanet.org'
issuerRef:
name: letsencrypt
kind: ClusterIssuer
But here is where I'd always get stuck. I would generate the cert and it would get stuck in pending forever and never actually get issued. I verified that the appropriate TXT records were in fact being created in cloudflare, so I started digging into what possibly could be wrong.
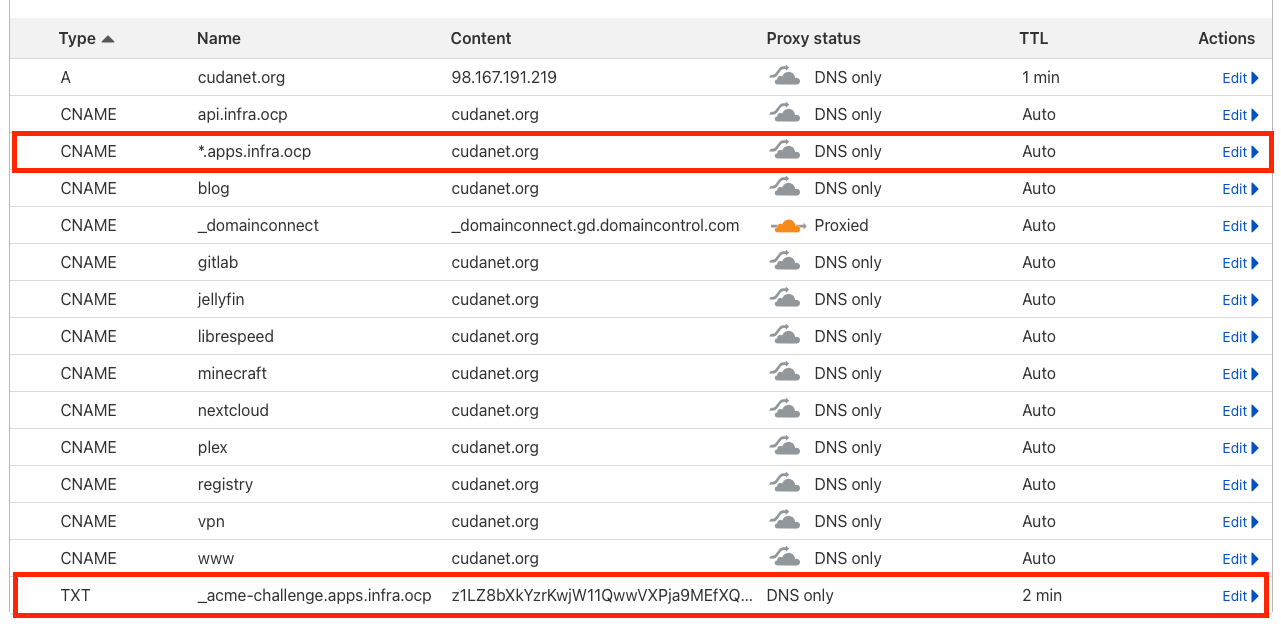
Checking the pod logs on the cert-manager controller revealed little, but it gave me a direction to start looking in
E0309 15:55:33.161540 1 sync.go:190] "cert-manager/challenges: propagation check failed" err="DNS record for \"apps.infra.ocp.cudanet.org\" not yet propagated" resource_name="letsencrypt-1-331836651-2183377533" resource_namespace="openshift-ingress" resource_kind="Challenge" resource_version="v1" dnsName="apps.infra.ocp.cudanet.org" type="DNS-01"It's always DNS. So, if I can log in to Cloudflare and see that the TXT record was created, but the pods on Openshift are saying that it doesn't exist, what seems to be the holdup? On a hunch I guessed that my DNS server was caching an invalid response and preventing the cert from being generated. I ran a dig against the TXT record from my workstation - no dice. Okay, I think I'm on to something. I cleared my DNS cache (something I seem to have to do FAR too often lately) sudo killall -HUP mDNSResponder and re-ran the dig command. Bingo! I got the TXT record response I was expecting. Of course... it was DNS. It's always DNS.
So how do I go about fixing this? Well, there are actually several options on OPNsense for how to manage DNS baked in. The default is unbound which is the most well documented and easy to use. The other option is dnsmasq, which I had used in the past when I still used DD-WRT on an old Netgear Nighthawk router before moving on to pfSense (and later OPNsense). I knew at this point that DNS caching was the problem, and unfortunately there is no way to disable caching on unbound. That's not a bug, that's a feature. Unbound is first and foremost a local cache, and a forwarder second. It extensively relies on caching which in theory for the majority of use cases should actually improve DNS performance. Dnsmasq on the other hand can be configured as a pure forwarder. I knew what needed to be done...

I was apprehensive about ripping out my (mostly) functioning unbound DNS config and migrating to dnsmasq. Thankfully, switching between the two on OPNsense is simply a matter of turning one service off and turning on the other one, and you can configure things like overrides while either service is disabled, making the migration a lot easier.
The process of converting from unbound to dnsmasq was pretty straightforward for the most part. Start with the low hanging fruit - recreate all the host records . These would be all of your A records (overrides) and CNAMEs (aliases). Tedious, time consuming, but pretty much dummy proof.
Like unbound, creating anything other than A records or CNAMEs is considered 'advanced'. This includes wildcards and SRV records. Thankfully, you can pretty easily convert from unbound advanced configs to dnsmasq just using sed. For example, here's the config file that unbound uses for my prod OCP cluster:
server:
local-zone: "apps.okd.cudanet.org" redirect
local-data: "apps.okd.cudanet.org 86400 IN A 192.168.10.30"
local-data: "_etcd-server-ssl._tcp.okd.cudanet.org 86400 IN SRV 0 10 2380 etcd-1.okd.cudanet.org"
local-data: "_etcd-server-ssl._tcp.okd.cudanet.org 86400 IN SRV 0 10 2380 etcd-2.okd.cudanet.org"
local-data: "_etcd-server-ssl._tcp.okd.cudanet.org 86400 IN SRV 0 10 2380 etcd-3.okd.cudanet.org"where the first two lines, the local-zone redirect to 192.168.10.30 are the wildcard entry for my Ingress VIP on my prod OKD cluster and the next 3 entries are SRV records required for etcd. For unbound on OPNsense, unbound config files reside at /usrl/local/etc/unbound.opnsense.d/
And here is the equivalent dnsmasq conf file
address=/apps.okd.cudanet.org/192.168.10.30
domain=etcd-1.okd.cudanet.org
srv-host=_etcd-server-ssl._tcp.okd.cudanet.org,2380
domain=etcd-2.okd.cudanet.org
srv-host=_etcd-server-ssl._tcp.okd.cudanet.org,2380
domain=etcd-2.okd.cudanet.org
srv-host=_etcd-server-ssl._tcp.okd.cudanet.org,2380a single SRV record consists of two lines on dnsmasq, first the domain directive indicates the A record or CNAME the SRV record resolves to and the srv-host directive is where you configure the DNS record and port, eg; _etcd-server-ssl._tcp.okd.cudanet.org on port 2380. As you can see, the way you declare custom entries isn't terribly different between dnsmasq and unbound. For dnsmasq on OPNsense, dnsmasq config files reside at /usr/local/etc/dnsmasq.conf.d/
I also use OPNsense as my only DNS server without any forwards or redirects so I had to recreate the appropriate SRV records for LDAP and Kerberos to authenticate to Active Directory
unbound AD config
local-data: "_ldap._tcp.8cee5fb4-c1cc-46d6-acdc-65f8ce1226dd.domains._msdcs.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_kerberos.tcp.Default-First-Site-Name._sites.dc._msdcs.cudanet.org IN SRV 0 100 88 addc01.cudanet.org"
local-data: "_ldap.tcp.Default-First-Site-Name._sites.dc._msdcs.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_kerberos._tcp.dc._msdcs.cudanet.org IN SRV 0 100 88 addc01.cudanet.org"
local-data: "_ldap._tcp.dc._msdcs.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_ldap._tcp.Default-First-Site-Name._sites.gc._msdcs.cudanet.org IN SRV 0 100 3268 addc01.cudanet.org"
local-data: "_ldap._tcp.gc._msdcs.cudanet.org IN SRV 0 100 3268 addc01.cudanet.org"
local-data: "_ldap._tcp.pdc._msdcs.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_ldap._tcp.Default-First-Site-Name._sites.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_kerberos._tcp.Default-First-Site-Name._sites.cudanet.org IN SRV 0 100 88 addc01.cudanet.org"
local-data: "_gc._tcp.Default-First-Site-Name._sites.cudanet.org IN SRV 0 100 3268 addc01.cudanet.org"
local-data: "_ldap._tcp.cudanet.org IN SRV 0 100 3268 addc01.cudanet.org"
local-data: "_kbpasswd._tcp.cudanet.org IN SRV 0 100 464 addc01.cudanet.org"
local-data: "_kerberos._tcp.cudanet.org IN SRV 0 100 88 addc01.cudanet.org"
local-data: "_gc._tcp.cudanet.org IN SRV 0 100 3268 addc01.cudanet.org"
local-data: "_kbpasswd._udp.cudanet.org IN SRV 0 100 464 addc01.cudanet.org"
local-data: "_kerberos._udp.cudanet.org IN SRV 0 100 88 addc01.cudanet.org"
local-data: "_ldap._tcp.DomainDnsZones.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_ldap.Default-First-Site-Name._sites.DomainDnsZones.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_ldap.Default-First-Site-Name._sites.ForestDnsZones.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_ldap._tcp._sites.ForestDnsZones.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"
local-data: "_ldap._tcp._sites.ForestDnsZones.cudanet.org IN SRV 0 100 389 addc01.cudanet.org"dnsmasq AD config
domain=addc01.cudanet.org
srv-host=_ldap._tcp.8cee5fb4-c1cc-46d6-acdc-65f8ce1226dd.domains._msdcs.cudanet.org,addc01.cudanet.org,389
srv-host=_kerberos.tcp.Default-First-Site-Name._sites.dc._msdcs.cudanet.org,addc01.cudanet.org,88
srv-host=_ldap.tcp.Default-First-Site-Name._sites.dc._msdcs.cudanet.org,addc01.cudanet.org,389
srv-host=_kerberos._tcp.dc._msdcs.cudanet.org,addc01.cudanet.org,88
srv-host=_ldap._tcp.dc._msdcs.cudanet.org,addc01.cudanet.org,389
srv-host=_ldap._tcp.Default-First-Site-Name._sites.gc._msdcs.cudanet.org,addc01.cudanet.org,3268
srv-host=_ldap._tcp.gc._msdcs.cudanet.org,addc01.cudanet.org,3268
srv-host=_ldap._tcp.pdc._msdcs.cudanet.org,addc01.cudanet.org,389
srv-host=_ldap._tcp.Default-First-Site-Name._sites.cudanet.org,addc01.cudanet.org,389
srv-host=_kerberos._tcp.Default-First-Site-Name._sites.cudanet.org,addc01.cudanet.org,88
srv-host=_gc._tcp.Default-First-Site-Name._sites.cudanet.org,addc01.cudanet.org,3268
srv-host=_ldap._tcp.cudanet.org,addc01.cudanet.org,3268
srv-host=_kbpasswd._tcp.cudanet.org,addc01.cudanet.org,464
srv-host=_kerberos._tcp.cudanet.org,addc01.cudanet.org,88
srv-host=_gc._tcp.cudanet.org,addc01.cudanet.org,3268
srv-host=_kbpasswd._udp.cudanet.org,addc01.cudanet.org,464
srv-host=_kerberos._udp.cudanet.org,addc01.cudanet.org,88
srv-host=_ldap._tcp.DomainDnsZones.cudanet.org,addc01.cudanet.org,389
srv-host=_ldap.Default-First-Site-Name._sites.DomainDnsZones.cudanet.org,addc01.cudanet.org,389
srv-host=_ldap.Default-First-Site-Name._sites.ForestDnsZones.cudanet.org,addc01.cudanet.org,389
srv-host=_ldap._tcp._sites.ForestDnsZones.cudanet.org,addc01.cudanet.org,389
srv-host=_ldap._tcp._sites.ForestDnsZones.cudanet.org,addc01.cudanet.org,389
domain=addc02.cudanet.org
srv-host=_ldap._tcp.8cee5fb4-c1cc-46d6-acdc-65f8ce1226dd.domains._msdcs.cudanet.org,addc02.cudanet.org,389
srv-host=_kerberos.tcp.Default-First-Site-Name._sites.dc._msdcs.cudanet.org,addc02.cudanet.org,88
srv-host=_ldap.tcp.Default-First-Site-Name._sites.dc._msdcs.cudanet.org,addc02.cudanet.org,389
srv-host=_kerberos._tcp.dc._msdcs.cudanet.org,addc02.cudanet.org,88
srv-host=_ldap._tcp.dc._msdcs.cudanet.org,addc02.cudanet.org,389
srv-host=_ldap._tcp.Default-First-Site-Name._sites.gc._msdcs.cudanet.org,addc02.cudanet.org,3268
srv-host=_ldap._tcp.gc._msdcs.cudanet.org,addc02.cudanet.org,3268
srv-host=_ldap._tcp.pdc._msdcs.cudanet.org,addc02.cudanet.org,389
srv-host=_ldap._tcp.Default-First-Site-Name._sites.cudanet.org,addc02.cudanet.org,389
srv-host=_kerberos._tcp.Default-First-Site-Name._sites.cudanet.org,addc02.cudanet.org,88
srv-host=_gc._tcp.Default-First-Site-Name._sites.cudanet.org,addc02.cudanet.org,3268
srv-host=_ldap._tcp.cudanet.org,addc02.cudanet.org,3268
srv-host=_kbpasswd._tcp.cudanet.org,addc02.cudanet.org,464
srv-host=_kerberos._tcp.cudanet.org,addc02.cudanet.org,88
srv-host=_gc._tcp.cudanet.org,addc02.cudanet.org,3268
srv-host=_kbpasswd._udp.cudanet.org,addc02.cudanet.org,464
srv-host=_kerberos._udp.cudanet.org,addc02.cudanet.org,88
srv-host=_ldap._tcp.DomainDnsZones.cudanet.org,addc02.cudanet.org,389
srv-host=_ldap.Default-First-Site-Name._sites.DomainDnsZones.cudanet.org,addc02.cudanet.org,389
srv-host=_ldap.Default-First-Site-Name._sites.ForestDnsZones.cudanet.org,addc02.cudanet.org,389
srv-host=_ldap._tcp._sites.ForestDnsZones.cudanet.org,addc02.cudanet.org,389
srv-host=_ldap._tcp._sites.ForestDnsZones.cudanet.org,addc02.cudanet.org,389It looks scarier than it actually is. Just take your time and make sure you get everything converted over correctly.
Now, here's the real kicker. By default, dnsmasq will also do caching and in my brief testing with caching enabled, DNS resolution performance seemed pretty slow. I didn't benchmark it or anything but anecdotally it just seemed to be sluggish. Pages would take a few extra seconds to load, pings would take a second before they started responding. Disabling cacheing entirely dramatically improved DNS resolution performance. Not that I'd ever thought that my previously working unbound config was sluggish, but I immediately noticed that DNS lookups were almost instantaneous.
In order to disable cache on dnsmasq, you simply set the cache size to zero. I also limited the number of maximum concurrent queries to 100. Limiting the concurrency of queries (default value is 5000) can reduce load and improve overall performance in most cases. I might need to do some fine tuning here, but for now everything in my home network seems to be working better than ever
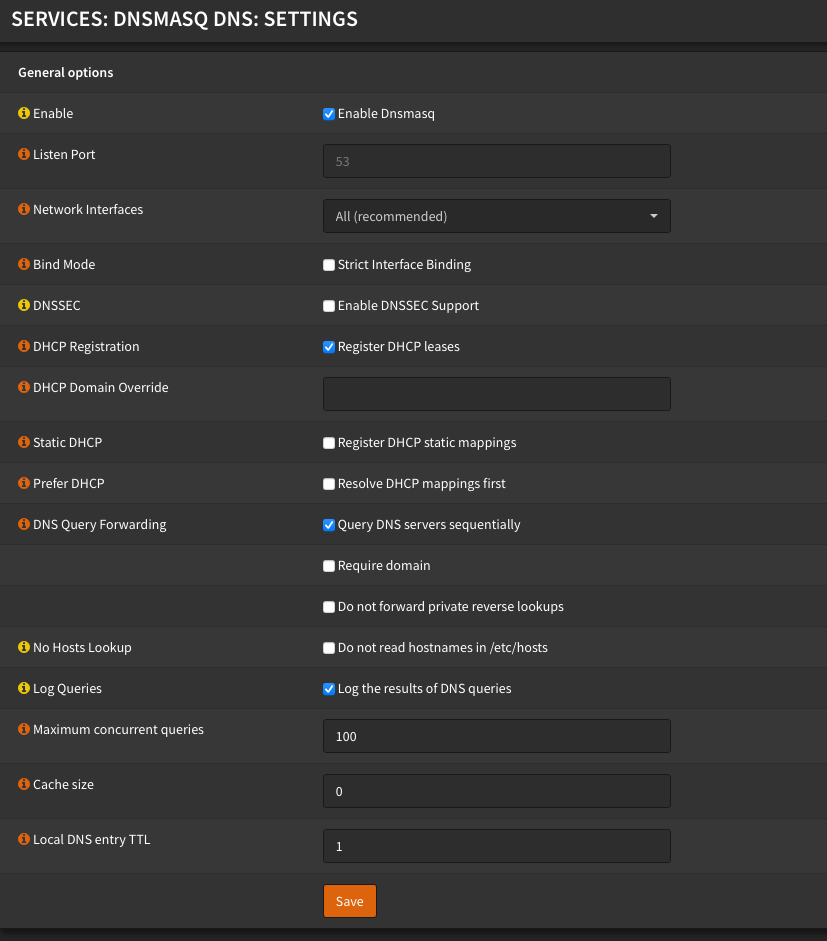
I did a few spot checks to make sure that my Openshift clusters were up and things like LDAP were working. I was satisfied that everything had been successfully migrated over from unbound to dnsmasq. All in all, the process took about an hour total to convert everything over.
The moment of truth
Fully migrated over to dnsmasq, I went back to the original issue that I went down this DNS rabbit hole trying to fix - automatic certificate rotation. I took a look at the openshift-ingress cert that I'd tried to generate and it was still stuck in pending. Rather than spend time trying to troubleshoot cert-manager with any residual weirdness left over from unbound, I decided to fully uninstall the operator and perform a fresh install.
This time, when I requested the new cert, after about a minute the status went from pending to ready. Success! Switching from unbound to dnsmasq (and perhaps more importantly, disabling DNS caching) had finally fixed my problems with cert-manager, and I'll never have to worry about an expired certificate ever again!

Next Steps
Being able to generate a cert automatically is great, but in order to actually use that cert with a service on Openshift will require a bit more work. My research on the topic revealed that there are a few different methods for integrating cert-manager with services. For ingress type services, you can specify a secret generated by cert-manager, eg;
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
labels:
name: gitlab-webservice-default
namespace: gitlab-system
spec:
ingressClassName: gitlab-nginx
rules:
- host: gitlab.apps.infra.ocp.cudanet.org
http:
paths:
- backend:
service:
name: gitlab-webservice-default
port:
number: 8181
path: /
pathType: Prefix
tls:
- hosts:
- gitlab.apps.infra.ocp.cudanet.org
secretName: letsencryptwhere letsencrypt is the name of the certificate and gitlab-webservice-default is the name of the ingress. However, I'm really not a fan of ingresses or load balancers unless they are absolutely necessary because I don't like managing a bunch of IP addresses and complicated DNS. I try to stick with the wildcard ingress for my cluster and use routes to create 'pretty' URLs that are externally accessible. I generally shy away from ingress in favor of the Red Hat method of exposing a deployment as a clusterIP service and provisioning a route exposing that service. However, without knowing the certificate, CA and private key prior to creating a route, you can't have valid SSL termination, and you can't simply point a route at a TLS secret and call it a day.
To extend routes with cert-manager functionality, you need an add-on that will allow you to automatically create routes with valid SSL (assuming they resolve properly to external DNS entries). You can use this project here https://github.com/cert-manager/openshift-routes
and create a route with the appropriate annotations like this:
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
cert-manager.io/issuer-kind: ClusterIssuer
cert-manager.io/issuer-name: letsencrypt
labels:
app: ghost
app.kubernetes.io/component: ghost
app.kubernetes.io/instance: ghost
name: ghost
namespace: blog
spec:
host: ghost-blog.apps.infra.ocp.cudanet.org
port:
targetPort: 2368-tcp
to:
kind: Service
name: ghost
weight: 100
wildcardPolicy: Nonewhere letsencrypt is the name of the ClusterIssuer I configured for cert-manager. You can also use a namespaced Issuer. After creating the route, it will take about a minute to generate a certificate and automatically populate out the spec.tls section of the route. After it's done the final result will look something like this:
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
cert-manager.io/certificate-revision: "1"
cert-manager.io/issuer-kind: ClusterIssuer
cert-manager.io/issuer-name: letsencrypt
kubectl.kubernetes.io/last-applied-configuration: |
...
labels:
app: ghost
app.kubernetes.io/component: ghost
app.kubernetes.io/instance: ghost
name: ghost
namespace: blog
spec:
host: ghost-blog.apps.infra.ocp.cudanet.org
port:
targetPort: 2368-tcp
tls:
certificate: |
-----BEGIN CERTIFICATE-----
MIIFFzCCA/+gAwIBAgISBDT0GEBSQdok9ivqp9/5JgkiMA0GCSqGSIb3DQEBCwUA
...
4gb+6cPlzc4JrD8=
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
MIIFFjCCAv6gAwIBAgIRAJErCErPDBinU/bWLiWnX1owDQYJKoZIhvcNAQELBQAw
...
nLRbwHOoq7hHwg==
-----END CERTIFICATE-----
insecureEdgeTerminationPolicy: Redirect
key: |
-----BEGIN RSA PRIVATE KEY-----
MIIEogIBAAKCAQEAvbxkVLJDhIkHJqRAf22nDfCAVEbf/ZpdVQ4wRZkauYXW/ftQ
...
A30wcafLGFll5bR8mw1SjSxAUpA7RILcPJ6qjL9VLSt5r63wpsM=
-----END RSA PRIVATE KEY-----
termination: edge
to:
kind: Service
name: ghost
weight: 100
wildcardPolicy: None
The second method you could use this project here https://github.com/redhat-cop/cert-utils-operator which accomplishes largely the same thing as openshift-routes but is available as an operator, and references an existing cert already generated by cert-manager which in my mind makes it a littel more gitops-y.
With cert-manager already installed and configured, just install the cert-utils-operator from the Operator hub
Once installed, from within the namespace you want to use cert-manager generated certs with routes in, first create a cert like this
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: letsencrypt
namespace: blog
spec:
secretName: letsencrypt
secretTemplate:
duration: 2160h0m0s # 90d
renewBefore: 360h0m0s # 15d
commonName: 'blog.cudanet.org'
usages:
- server auth
- client auth
dnsNames:
- 'blog.cudanet.org'
issuerRef:
name: letsencrypt
kind: ClusterIssuerOnce the cert has been issued, you should have a secret named letsencrypt. Then create a route specifying that cert with an annotation like this:
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: blog
namespace: blog
annotations:
cert-utils-operator.redhat-cop.io/certs-from-secret: "letsencrypt"
spec:
host: blog.cudanet.org
to:
kind: Service
name: ghost
weight: 100
port:
targetPort: 2368-tcp
tls:
termination: edge
insecureEdgeTerminationPolicy: Redirect
wildcardPolicy: Noneworth noting, using the cert-utils-operator method, you must use either edge or reencrypt to terminate TLS. The end result will be a route like this
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
cert-utils-operator.redhat-cop.io/certs-from-secret: letsencrypt
kubectl.kubernetes.io/last-applied-configuration: | ...
creationTimestamp: "2024-03-11T15:50:15Z"
name: blog
namespace: blog
spec:
host: blog.cudanet.org
port:
targetPort: 2368-tcp
tls:
certificate: |
-----BEGIN CERTIFICATE-----
MIIE7TCCA9WgAwIBAgISBFmodBbTw5vUmuyXh03HoH2/MA0GCSqGSIb3DQEBCwUA
...
i+i3UuFXuYpg4soOnFDP7jQ=
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
MIIFFjCCAv6gAwIBAgIRAJErCErPDBinU/bWLiWnX1owDQYJKoZIhvcNAQELBQAw
...
nLRbwHOoq7hHwg==
-----END CERTIFICATE-----
insecureEdgeTerminationPolicy: Redirect
key: |
-----BEGIN RSA PRIVATE KEY-----
MIIEpAIBAAKCAQEAt6rGZ9E2jzeeX2NVSLZCI1URnSdhaVhEIghWAn41sHcaUasa
...
MByQ+SwuLOm4bMpKg2YvZVFP7e99vTeGzj1KPR70ePPp3EW6A49uvw==
-----END RSA PRIVATE KEY-----
termination: edge
to:
kind: Service
name: ghost
weight: 100
wildcardPolicy: None
Either method works fine with routes, but given the choice between the two I kind of prefer the cert-utils-operator method.
Going further
So that's it in a nutshell if you have a single cluster, but what about environments where you have multiple clusters on the same network (like me)? They can't all be exposed on your WAN since you can only NAT a single endpoint port.
There's probably a dozen ways to solve this problem, but regardless of which method you take, it boils down to relaying your clusters (and non OCP services) through a reverse proxy. This could theoretically be any number of solutions; HAproxy, nginx, traefik, etc. Basically you just need something that can redirect HTTP/HTTPS (and sometimes other protocols) from one place to another. In the past, I've used nginx for this because... well, it's what I've used for years. It's pretty easy to understand and it just works. I've kicked around the idea of handling reverse proxy using Traefik. I need to decided where reverse proxy is going to sit. You could run it as a service on your router, you could run it on a VM, or even as a docker container on a desktop. My entire hosting environment consists of Openshift/OKD, so it ends up creating a chicken:egg/all-eggs-in-one-basket (choose your poultry based analogy) where I have the infrastructure serving reverse proxy also consuming that service.
In the past, I just ran a privileged nginx pod (necessary for reverse proxy to work) on my prod cluster reverse proxying the ingress and API URLs through the prod cluster ingress exposed as routes with TLS passthru (not as scary as it sounds).
First things first, make sure you have enabled wildcard routes on the IngressController (if you haven't already done so for configuring HCP)
oc edit IngressController -n openshift-ingress-operatorThen add two lines to spec
spec:
routeAdmission:
wildcardPolicy: WildcardsAllowedThen you need to create an SSL cert in your reverse proxy project. You can limit it to just the wildcard route for your reverse proxied cluster, but I included SANs for everything my reverse proxy pod might be handling.
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: letsencrypt
namespace: reverse-proxy
spec:
secretName: letsencrypt
secretTemplate:
duration: 2160h0m0s # 90d
renewBefore: 360h0m0s # 15d
commonName: '*.cudanet.org'
usages:
- server auth
- client auth
dnsNames:
- '*.cudanet.org'
- '*.apps.infra.ocp.cudanet.org'
- 'api.infra.ocp.cudanet.org'
- '*.apps.sno.ocp.cudanet.org'
- 'api.sno.ocp.cudanet.org'
- '*.apps.okd.cudanet.org'
- 'api.okd.cudanet.org'
issuerRef:
name: letsencrypt
kind: ClusterIssuerThen you basically you just add a stanza to your nginx.conf like this:
server {
listen 443;
server_name *.apps.sno.ocp.cudanet.org;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto "https";
proxy_ssl_name $host;
proxy_ssl_server_name on;
proxy_ssl_session_reuse off;
proxy_set_header Host $host:$server_port;
proxy_pass https://192.168.10.254:443;
}
}There's no one "right" way to manage an nginx pod, but I like to make things as easy on myself as possible. I provide the nginx.conf file as a configmap and pull the SSL cert and private key in from the letsencrypt secret I created above. My deployment looks like this
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
labels:
app: reverse-proxy
app.kubernetes.io/component: reverse-proxy
app.kubernetes.io/instance: reverse-proxy
name: reverse-proxy
namespace: reverse-proxy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
deployment: reverse-proxy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
deployment: reverse-proxy
spec:
containers:
- image: registry.cudanet.org/cudanet/reverse-proxy/nginx
imagePullPolicy: IfNotPresent
name: reverse-proxy
ports:
- containerPort: 80
name: 80-tcp
protocol: TCP
- containerPort: 443
name: 443-tcp
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/nginx/nginx.conf
name: nginxconf
readOnly: true
subPath: nginx.conf
- mountPath: /etc/nginx/fullchain.pem
name: tlscrt
readOnly: true
subPath: fullchain.pem
- mountPath: /etc/nginx/privkey.pem
name: tlskey
readOnly: true
subPath: privkey.pem
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: reverse-proxy
serviceAccountName: reverse-proxy
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
items:
- key: nginx.conf
path: nginx.conf
name: nginxconf
name: nginxconf
- name: tlscrt
secret:
defaultMode: 420
items:
- key: tls.crt
path: fullchain.pem
secretName: letsencrypt
- name: tlskey
secret:
defaultMode: 420
items:
- key: tls.key
path: privkey.pem
secretName: letsencryptAs you can see in the example, I mount the the configmap and secret as volumes directly on the pod - no need for a PVC. This way all I have to do when I make changes to the nginx.conf is update the configmap and bounce the pod. The cert will never expire because cert-manager will auto-rotate it for me. Pretty slick. Next you need to create a wildcard route with edge TLS termination in your nginx reverse-proxy project like this:
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: sno-ingress
namespace: reverse-proxy
annotations:
cert-utils-operator.redhat-cop.io/certs-from-secret: "letsencrypt"
labels:
app: reverse-proxy
app.kubernetes.io/component: reverse-proxy
app.kubernetes.io/instance: reverse-proxy
spec:
host: console-openshift-console.apps.sno.ocp.cudanet.org
to:
kind: Service
name: https
weight: 100
port:
targetPort: 443
tls:
termination: edge
insecureEdgeTerminationPolicy: Redirect
wildcardPolicy: SubdomainIt's going to wrap your reverse proxied cluster ingress in valid SSL even if the ingress cert is expired or self signed on the next cluster, which is both good and bad. I do wish that it were possible to pass thru directly and get SSL terminated by the second cluster's ingress, but I wasn't able to get that working.
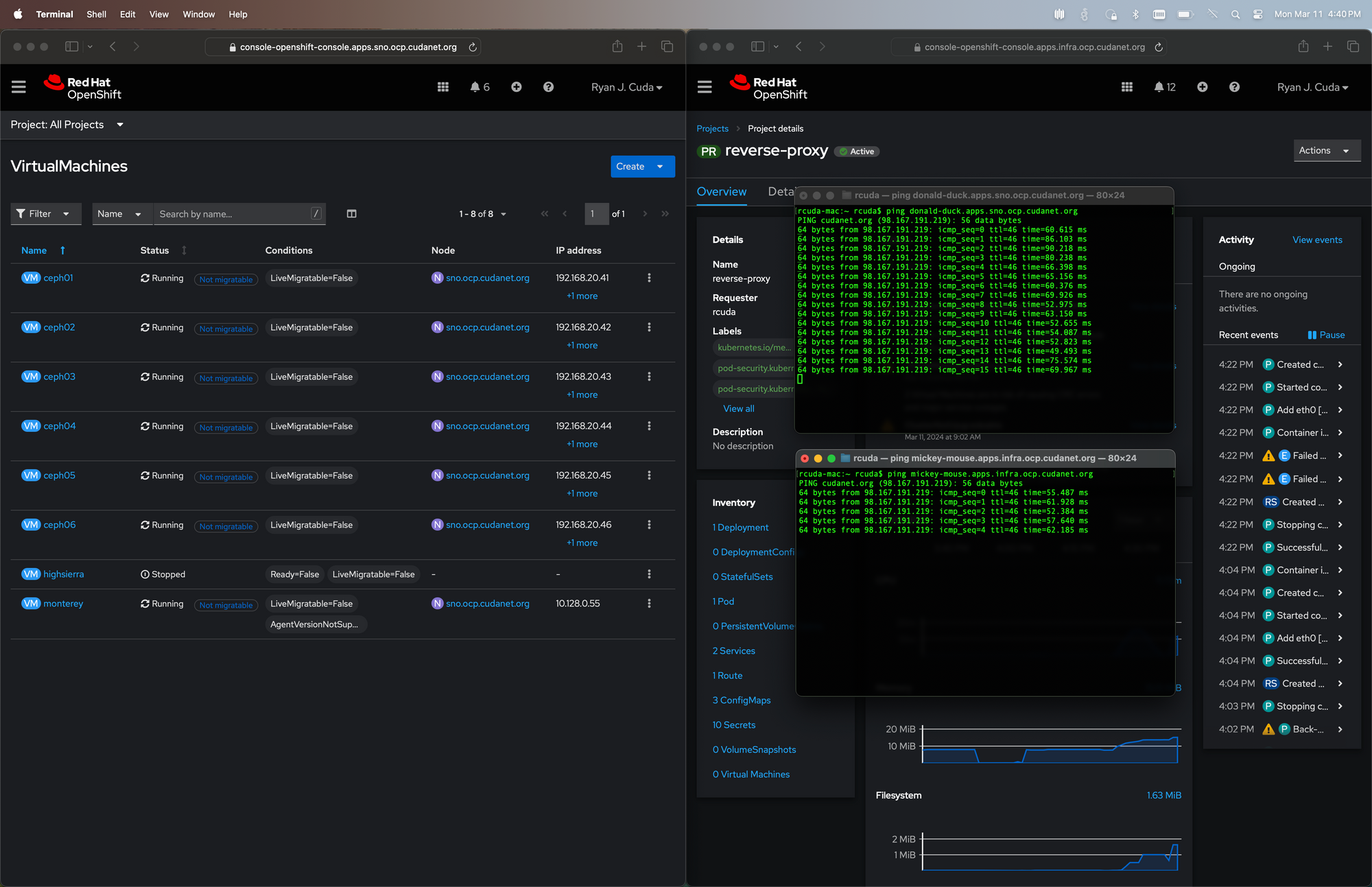
Here's a screenshot from my MacBook tethered to my phone and not connected to my wifi and not on VPN, proving that my reverse proxy is working, and that both cluster ingress wildcards resolve to the same IP address.
Technically we could lather-rinse-repeat for the reverse proxied cluster API and redirect from 6443 to 443, so that outside my network I can hit the API at eg; https://api.sno.ocp.cudanet.org:443. I'm not going to because I feel like that's just asking for trouble, but it is possible to do so.
And now, at long last we should be able to configure cert-manager on the second cluster as well now that we definitely have DNS and routing working.
From inside my network, my ingress is using a self-signed cert on my SNO cluster
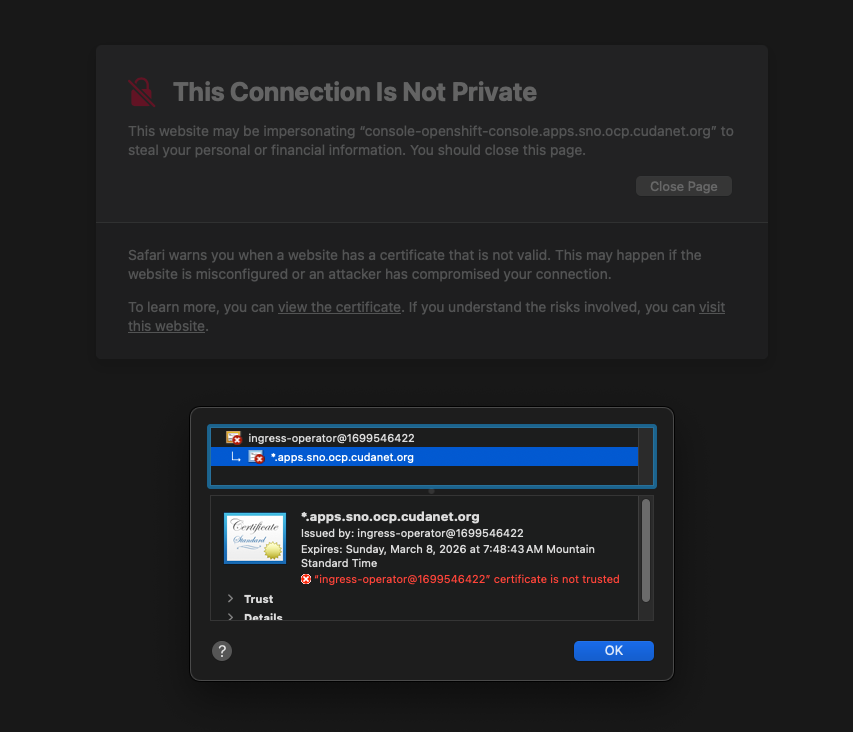
The steps are exactly the same on the second cluster as the first
- install cert-manager
- create a ClusterIssuer
- request a cert
- apply the cert to the ingress
That's all there is to it. Lather, rinse and repeat for any other clusters you have behind your firewall, and enjoy never having to rotate a cert manually again.