AMD GPU Passthrough on Openshift

One of my Openshift clusters is Intel, the other is AMD. In terms of CPU, they're pretty well matched - the Intel cluster using i7-7700T CPUs and the AMD cluster equipped with AMD Ryzen 5 PRO 2400GE. They're both 4 core, 8 thread and clock in right around 3Ghz (the AMD's being slightly faster at 3.2GHz), both are 35W CPUs. However, where the AMD processors have the real advantage is the Vega 11 GPU they come bundled with that is substantially more capable than the Intel HD 630 mobiel GPUs on the i7s.
After I was successfully able to pass through an Intel GPU to a container, I wanted to find out if it were possible to accomplish the same with the far more performant AMD GPUs available on my second Openshift cluster, by using this project here .
Long story short, I was able to get it working, but I'm not going to lie... the AMD GPU plugin lags pretty far behind Intel's device plugin operator in terms of functionality, ease of setup and documentation. But for the purpose of "I can pass a GPU through to a pod" - yeah. It get's the job done.
By default, this project likes to install things into the default and kube-system namespaces - neither of which I'm a fan of using, so I ended up modifying some things. I created a namespace called k8s-device-plugin where I installed this "operator" - and I use the term loosely because it hardly qualifies as an operator. It's just a daemonset. I had to modify the original config's securityContext with privileged: true in order to get it to work, but other than that it works as advertised. Here's my yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
annotations:
name: amdgpu-device-plugin-daemonset
namespace: k8s-device-plugin
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
name: amdgpu-dp-ds
template:
metadata:
creationTimestamp: null
labels:
name: amdgpu-dp-ds
spec:
containers:
- image: rocm/k8s-device-plugin
imagePullPolicy: Always
name: amdgpu-dp-cntr
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/kubelet/device-plugins
name: dp
- mountPath: /sys
name: sys
dnsPolicy: ClusterFirst
nodeSelector:
kubernetes.io/arch: amd64
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: amd-gpu-plugin
serviceAccountName: amd-gpu-plugin
terminationGracePeriodSeconds: 30
tolerations:
- key: CriticalAddonsOnly
operator: Exists
volumes:
- hostPath:
path: /var/lib/kubelet/device-plugins
type: ""
name: dp
- hostPath:
path: /sys
type: ""
name: sys
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdateOnce the pods came up, you can check that your nodes do in fact have an allocatable GPU, eg
oc get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\n'}{' amd.com/gpu: '}{.status.allocatable.amd\.com/gpu}{'\n'}"
which should come back with something like this
compute-node-1
amd.com/gpu: 1
compute-node-2
amd.com/gpu: 1
control-plane-1
amd.com/gpu: 1
control-plane-2
amd.com/gpu: 1
control-plane-3
amd.com/gpu: 1Then we can give a pod a GPU. In my test I spun up a jellyfin server. Here's my yaml
apiVersion: v1
items:
- apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
labels:
app: jellyfin-jellyfin
app.kubernetes.io/component: jellyfin-jellyfin
app.kubernetes.io/instance: jellyfin-jellyfin
name: jellyfin-jellyfin
namespace: jellyfin
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
deployment: jellyfin-jellyfin
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
openshift.io/generated-by: OpenShiftNewApp
creationTimestamp: null
labels:
deployment: jellyfin-jellyfin
spec:
containers:
- image: registry.cudanet.org/cudanet/jellyfin/jellyfin@sha256:2e83da8a61fc6088cc30e8cdba10ba79e122bad031f50b2d8b929a771bf44443
imagePullPolicy: IfNotPresent
name: jellyfin-jellyfin
ports:
- containerPort: 8096
protocol: TCP
resources:
limits:
amd.com/gpu: "1"
cpu: "1"
memory: 8Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /cache
name: jellyfin-volume-1
- mountPath: /config
name: jellyfin-volume-2
- mountPath: /media
name: jellyfin-volume-3
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- name: jellyfin-volume-1
persistentVolumeClaim:
claimName: jellyfin-volume-1
- name: jellyfin-volume-2
persistentVolumeClaim:
claimName: jellyfin-volume-2
- name: jellyfin-volume-3
persistentVolumeClaim:
claimName: jellyfin-volume-3The important part here is amd.com/gpu: "1" under resources > limits. If the pod spins up, the GPU should be working and you should see the device bound to /dev/dri/renderD128. Then you can test out hardware transcoding in Jellyfin by setting the following settings
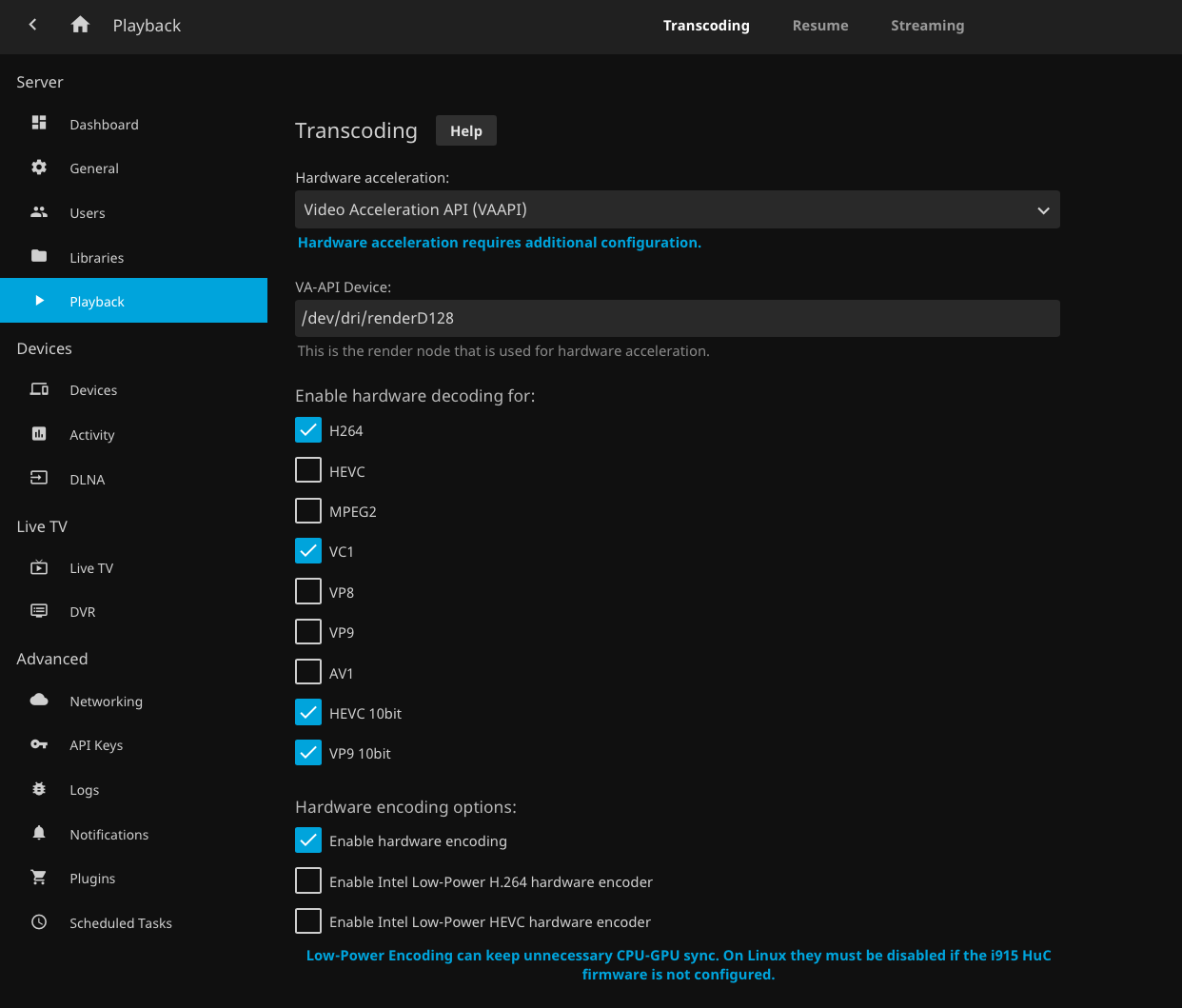
Set hardware acceleration to 'VAAPI' and select the new AMD GPU device (should be the only option). That's pretty much it. Jellyfin isn't quite as informative as Plex is about whether hardware acceleration is working or not, but if you can change the bitrate on a stream, it's working. And you should be able to see output in the pod logs about vaapi, eg;
`[9:05:59] [INF] [116] Jellyfin.Api.Helpers.TranscodingJobHelper: /usr/lib/jellyfin-ffmpeg/ffmpeg -analyzeduration 200M -init_hw_device vaapi=va:/dev/dri/renderD128 -filter_hw_device va -hwaccel vaapi -hwaccel_output_format vaapi -autorotate 0 -i file:"/media/A Charlie Brown Christmas.m4v" -autoscale 0 -map_metadata -1 -map_chapters -1 -threads 0 -map 0:0 -map 0:2 -map -0:s -codec:v:0 h264_vaapi -rc_mode VBR -b:v 292000 -maxrate 292000 -bufsize 584000 -profile:v:0 constrained_baseline -force_key_frames:0 "expr:gte(t,0+n_forced*3)" -vf "setparams=color_primaries=bt709:color_trc=bt709:colorspace=bt709,scale_vaapi=w=426:h=238:format=nv12:extra_hw_frames=24" -codec:a:0 libfdk_aac -ac 2 -ab 128000 -ar 44100 -copyts -avoid_negative_ts disabled -max_muxing_queue_size 2048 -f hls -max_delay 5000000 -hls_time 3 -hls_segment_type mpegts -start_number 0 -hls_segment_filename "/config/transcodes/098f32279748f20fd6a790c6ac629b51%d.ts" -hls_playlist_type vod -hls_list_size 0 -y "/config/transcodes/098f32279748f20fd6a790...That's all there is to it. Enjoy!